Управление оперативной памятью
 Волжский Университет имени В. Н. Татищева
Волжский Университет имени В. Н. Татищева
Факультет «Информатики и телекоммуникаций»
Кафедра «Информатика и системы управления»
Курсовая работа
по дисциплине:
“Основы программного обеспечения”
на тему:
“Управление оперативной памятью”
Содержание
Введение
1. Аналитический раздел
Определение
Принципы управления и распределения оперативной памяти
Разработка алгоритма управления оперативной памятью
Вывод
Список используемой литературы
Введение
В настоящее время существуют множество операционных программ, которые в достаточной степени эффективности и надежности, управляют оперативной памятью. К таким системам можно отнести Windows, Unix и т.д. Прогресс электроники привел к значительному улучшению элементов памяти. А именно таких параметров, модулей памяти, как объем, надежность, оперативность и компактность. Память применяется везде, где есть элемент, обрабатывающий информацию (процессор, контроллер). В следствии этого, появились новые, более мощные системы управления способные использовать ресурсы оперативной памяти. Это привело к увеличению скорости обработки информации и к увеличению мощности программных средств и следовательно самой мощи, всего компьютера в целом. Например, подсистема управления оперативной памятью MS-DOS базировалась на использовании блоков управления памятью MCB. Такое "управление" памятью полностью основано на джентльменском соглашении между программами о сохранении целостности операционной системы, так как любая программа может выполнить запись данных по любому адресу. Программа может легко разрушить системные области MS-DOS или векторную таблицу прерываний. На сегодняшний день существует приложение Windows, которое выполняется в защищенном режиме, поэтому оно не может адресоваться к любым областям памяти. Это сильно повышает надежность операционной системы.
Цель курсовой работы состоит в изучении функционирования и взаимодействие операционной системы с оперативной памятью. Так же будет выполнен анализ основных типов, параметров оперативной памяти применяемых в системных платах персонального компьютера. Далее будет представлена программная часть с обработкой и ходом выполнение команд и размещение в оперативной памяти.
1. Аналитический раздел
1.1 Определение
Оперативная (или рабочая) память компьютера - ОЗУ (Оперативное Запоминающее Устройство) - собрана на полупроводниковых кристаллах (чипах - chip) и хранит информацию, только пока компьютер включен. При выключении питания ее содержимое теряется. Иногда, эту память называют еще памятью с произвольным доступом.(Random Access Memory – RAM).
Всю память с произвольным доступом (RAM) можно разделить на два типа:
DRAM (динамическая RAM)
SRAM (статическая RAM).
Память типа DRAM
Динамическая оперативная память (Dynamic RAM – DRAM) используется в большинстве систем оперативной памяти персональных компьютеров. Основное преимущество этого типа памяти состоит в том, что ее ячейки интегрированы плотно, т.е. в небольшую микросхему можно поместить множество битов, а значит, на их основе можно построить память большей емкости.
Ячейки памяти в микросхеме DRAM – это крошечные конденсаторы, которые удерживают заряды. Проблемы, связанные с памятью этого типа, вызваны тем, что она динамическая, т.е. должна постоянно регенерироваться, так как в противном случае электрические заряды в конденсаторах памяти будут “стекать”, и данные будут потеряны. Регенерация происходит, когда контроллер памяти системы берет крошечный перерыв и обращается ко всем строкам данных в микросхемах памяти. Большинство систем имеет контроллер памяти (обычно встраиваемый в набор микросхем системной платы), который настроен на соответствующую промышленным стандартам частоту регенерации, равную 15 мкс.
Регенерация памяти, к сожалению, “отнимает время” у процессора: каждый цикл регенерации по длительности занимает несколько циклов центрального процессора. Некоторые системы позволяют изменить параметры регенерации с помощью программы установки параметров CMOS, но увеличение времени между циклами регенерации может привести к тому, что в некоторых ячейках памяти заряд “стечет”, а это вызовет сбой памяти.
В устройствах DRAM для хранения одного бита используется только один транзистор и пара конденсаторов, поэтому они более вместительны, чем микросхемы других типов памяти. Транзистор для каждого однозарядного регистра DRAM использует для чтения состояния смежного конденсатора. Если конденсатор заряжен, в ячейке записана-1; если заряда нет – записан 0. Разработчики DRAM нашли возможность осуществления передачи данных с помощью асинхронного интерфейса.
С асинхронным интерфейсом процессор должен ожидать, пока DRAM закончит выполнение своих внутренних операций, которые обычно занимают около 60 нс. С синхронным управлением DRAM происходит защелкивание информации от процессора под управлением системных часов. Триггеры запоминают адреса, сигналы управления и данных, что позволяет процессору выполнять другие задачи. После определенного количества циклов данные становятся доступны, и процессор может считывать их с выходных линий.
Другое преимущество синхронного интерфейса заключается в том, что системные часы задают только временные границы, необходимые DRAM. Это исключает необходимость наличия множества стробирующих импульсов. В результате упрощается ввод, т. к. контрольные сигналы адреса данных могут быть сохранены без участия процессора и временных задержек. Подобные преимущества также реализованы и в операциях вывода.
К первому поколению высокоскоростных DRAM главным образом относят EDO DRAM, SDRAM и RDRAM, а к следующему - DDR SDRAM, Direct RDRAM, SLDRAM и т. д.
SDRAM
SDRAM (Synchronous DRAM) – это тип динамической оперативной памяти DRAM, работа которой синхронизируется с шиной памяти. SDRAM передает информацию в высокоскоростных пакетах, Использующих высокоскоростной синхронизированный интерфейс. SDRAM позволяет избежать использования большинства циклов ожидания, необходимых при работе асинхронной DRAM, поскольку сигналы, по которым работает память такого типа, синхронизированы с тактовым генератором системной платы.
DDR SDRAM (SDRAM II)
DDR SDRAM (Double Data Rate SDRAM) является синхронной памятью, реализующей удвоенную скорость передачи данных по сравнению с обычной SDRAM.
DDR SDRAM не имеет полной совместимости с SDRAM, хотя использует метод управления, как у SDRAM, и стандартный 168-контактный разъем DIMM. DDR SDRAM достигает удвоенной пропускной способности за счет работы на обеих границах тактового сигнала (на подъеме и спаде), а SDRAM работает только на одной.
Direct Rambus DRAM - это высокоскоростная динамическая память с произвольным доступом, разработанная Rambus, Inc. Она обеспечивает высокую пропускную способность по сравнению с большинством других DRAM. Direct Rambus DRAMs представляет интегрированную на системном уровне технологию.
Память типа SRAM
Существует тип памяти, совершенно отличный от других, - статическая оперативная память (Static RAM – SRAM). Она названа так потому, что, в отличии от динамической оперативной памяти, для сохранения ее содержимого не требуется периодической регенерации. Но это не единственное ее преимущество. SRAM имеет более высокое быстродействие чем динамическая оперативная память, и может работать на той же частоте, что и современные процессоры.
Время доступа SRAM не более 2 нс, это означает, что такая память может работать синхронно с процессорами на частоте 500 МГц или выше. Однако для хранения каждого бита в конструкции SRAM используется кластер из 6 транзисторов. Использование транзисторов без каких либо конденсаторов означает, что нет необходимости в регенерации. Пока подается питание, SRAM будет помнить то, что сохранено.
Микросхемы SRAM не используются для всей системной памяти потому, что по сравнению с динамической оперативной памятью быстродействие SRAM намного выше, но плотность ее намного ниже, а цена довольно высокая. Более низкая плотность означает, что микросхемы SRAM имеют большие габариты, хотя их информационная емкость намного меньше. Большое число транзисторов и кластиризованное их размещение не только увеличивает габариты SRAM, но и значительно повышает стоимость технологического процесса по сравнению с аналогичными параметрами для микросхем DRAM.
Все выше перечисленные модули памяти размещаются в компьютере на главной системной плате или на отдельных платах памяти. Перед обработкой и выводом на экран данные сначала помещаются в память. Например, файлы прикладных программ обычно располагаются на жёстком диске. Когда Вы запускаете программу, её файлы загружаются в память для дальнейшей обработки. Также память обеспечивает временное хранение данных и прикладных программ. В общем случае, чем больше памяти установлено в компьютере, тем более сложные прикладные программы могут выполняться Вашим компьютером. Память служит для хранения данных (документов), обрабатываемых в текущий момент компьютером. Выполняемая программа, как и значительная часть операционной системы DOS, хранится в оперативной памяти. С точки зрения внутренних механизмов оболочки оперативная память делится на две части: основную и расширенную. Оперативная память Вашей системы может быть следующих видов:
- обычная или базовая память;
- дополнительная память;
- расширенная память;
- верхняя память.
Базовая память
Операционная система MS DOS, а, следовательно, и уподобляющее большинство работающих под ее управлением программ могут использовать лишь первый мегабайт памяти, который часто называют базовой памятью. Эта память в рамках ДОС поделена на две неравные части: первые 640 К (1К = 1024 байт) отводятся для программ пользователя и отдельных частей самой ДОС и называются стандартной памятью (conventional memory). Для использования стандартной памяти не нужны никакие дополнительные драйверы, поскольку операционная система MS-DOS изначально создана для работы в адресах 0-640 Кбайт. Оставшиеся 384 К зарезерервированы для памяти видеоадаптеров и ПЗУ и называются верхним блоком памяти (UMB - Uper Memory Block). В то же время в компьютерах IBM AT имеется возможность адресовать память объемом до 16 Mb, если в них используется микропроцессор 80286, или до 4 Gb, если используется микропроцессор 80386 или 80486. Объем непосредственно адресуемой оперативной памяти определяется разрядностью адресной шины микропроцессора. Микропроцессоры 8088 и 8086 имеют 20-разрядную шину, поэтому адресуют 2 в степени 20 = 1048576 байт = 1 Мb. Микропроцессор 80286 оснащен 24-разрядной шиной и адресует 2 в степени 24 = 16 777 216 байт = 16 Mb. 32-разрядная шина 80386 и 80486 микропроцессоров адресует 2 в степени 32 = 4294967296 байт = 4Gb.
Дополнительная память
Память ПК, остающаяся за вычетом первого мегабайта (т.е. за вычетом базовой памяти), называется дополнительной (Extended Memory). Дополнительная память является естественным дополнением к обычной (базовой) памяти компьютера, на что и указывает само её название. Однако единственный (но, к сожалению, определяющий) факт, в котором нет никакой естественности, заключается в том, что подавляющему большинству программ MS DOS она не доступна! Чтобы использовать дополнительную память, процессор компьютера должен работать в специальном режиме, называемом защищённым. А операционнная система MS DOS не поддерживает этого режима процессора. Таким образом, владелец современного компьютера IBM AT, оснащенного памятью, скажем, в 8 Mb, часто либо вообще не использует дополнительные 7 Mb, либо размещает в них электронный диск или буферную кэш-память для дисков. В версии Турбо Паскаля 7.0 (точнее, в пакете Borland Pascal with Objects 7.0) введена поддержка защищенного режима микропроцессоров 80286/ 80386/80486, в котором используется дополнительная память. Однако эта поддержка не касается стандартных средств работы с дополнительной памятью. Тем не менее отдельные программы MS DOS применяют технологию "расширения MS DOS", которая позволяет им воспользоваться преимуществами дополнительной памяти. Примером таких программ служат Lotus 1-2-3 (Lotus Development Corporation) и Paradox 386 (Borland International). Компьютеры же на базе микропроцессоров Intel 8086 и 8088 не могут иметь дополнительную память, т.к. не имеют защищённого режима. Эти микропроцессоры функционируют исключительно в реальном режиме и поэтому не годятся для работы с программами, использующими дополнительную память. Дополнительную память иногда называют XMS-памятью; XMS - сокращение от eXtended Memory Specification (спецификация дополнительной памяти). Не путайте эту аббревиатуру с другой - EMS (Expanded Memory
Расширенная память
Ранние IBM-совместимые ПК типа IBM PC/XT оснащались микропроцессорами 8088 или 8086, способными работать с оперативной памятью емкостью не более 1 Мбайт. Несмотря на значительные размеры этой памяти, в ряде прикладных программ ее оказывается недостаточио. Такие программы вынуждены интенсивно использовать диск для размезщения больших объемов данных, что сильно снижает их производительность. Поэтому почти одновременно с появлением компьютеров IBM PC/XT начались поиски путей повышения производительности крупных прикладных пропоим (табличных процессоров, систем управления базами данных и т.п.) за счет использования оперативной памяти большего чем 1 Мбайт размера. Эти поиски привели к выработке соглашения между ведущими фирмами-разработчиками программно-аппаратных средств, которое известно как EMS LIM (от Expanded Memory Specification - спецификация расширенной памяти, удовлетворяющая стандарту фирм Lotus-Intel-Microsoft). В соответствии с этим стандартом ПК оснащаются специальными EMS-платами, содержащими собственно расширенную память микросхемы, обеспечивающие доступ к ней. Память, организованная по принципам спецификации EMS, называется расширенной памятью. На компьютерах с микропроцессорами 80386 и 80486 расширенная память может эмулироваться программно. Начиная с версии 4.0 операционная система MS DOS поставляется с драйверами расширенной памяти XMAEM.SYS и XMA2EMS.SYS. В DOS 5.0 их функции выполняет драйвер EMM386.SYS. Последний на ПК с микропроцессорами 80386/80486 обеспечивает эмуляцию расширенной памяти, т.е. программно реализует функции EMS-платы и преобразует дополнительную память в расширенную. Кроме того, драйвер EMM386.SYS создает блоки верхней памяти (UMB).
Для функционирования драйвера EMM386.SYS требуется обеспечить поддержку расширенной памяти, которую осуществляет драйвер HIMEM.SYS. При этом драйвер HIMEM.SYS должен быть загружен до драйвера EMM386.SYS, поэтому строка DEVICE=HIMEM.SYS в файле CONFIG.SYS должна предшествовать строке DEVICE=EMM386.SYS. Таким образом, дополнительная память - это просто добавочная память. Расширенная память - это специальная добавочная память, удовлетворяющая требованиям спецификации EMS. Следует отметить, что термины "дополнительная" и "расширенная" память применяются только в операционной системе DOS. В других операционных системах, например, в OS/2, Unix или Windows NT можно использовать всю память компьютера. В этих операционных системах память называется просто "памятью".
Верхняя память
Помимо базовой, расширенной и дополнительной памяти, в ПК существует еще так называемая верхняя память (не путайте с верхним блоком памяти!). Как известно, 20-разрядный адрес при работе ПК в реальном режиме образуется путем сложения двух 16-разрядных слов - сегмента и смещения. Перед сложением сегмент смещается на 4 разряда влево (умножается на 16), что и обеспечивает 20-разрядный результат сложения - адрес конкретного байта. Формальное сложение сегмента и смещения может привести к переполнению 20-разрядной адресной сетки. Действительно, если, например, сегмент S=$FFFF, а смещение O=$0010, то сложение $FFFF*16 + $0010 дает значение $100000, для представления которого требуется уже 21 разряд. Поскольку в ПК применяется 20-разрядная шина, переполнение результата не может использоваться, и "лишний" 21-й разряд просто теряется, т.е, адресация с сегментом S= $FFFF и смещением O> $000F эквивалентна адресации с сегментом S= $0000 и смещением O= O - $0010. В адресной шине IBM AT имеется 21-й разряд, но его использование обычно запрещено. Однако в таких компьютерах предусмотрена возможность программного управления 21-м разрядом. Если этот разряд разблокировать, программе, работающей в реальном режиме процессора, станут доступны еще почти 64 К (без 16 байт). Эта часть памяти и называется верхней (High Memory Area). MS DOS версии 5.0 и некоторые совместимые с ней операционные системы других фирм (например, DR-DOS фирмы Digital Research версии 4.0 и выше) могут размещать в верхней памяти свои резидентные части, тем самым освобождая драгоценную стандартную память для программ пользователя. Таким образом, существуют 4 вида оперативной памяти: • базовая - с адресами от $00000 до $FFFFF; • верхняя - с адресами от $100000 до $10FFEF; • дополнипельная - с адресами от $100000 до $FFFFFFFF; • расширенная - организуется специальными аппаратными средствами на компьютерах с микропроцессорами 8088, 8086, 80286 и может программно эмулироваться на процессорах 80386 и 80486.
1.2 Принципы управления и распределения оперативной памяти
Основной ресурс системы, распределением которого занимается ОС - это оперативная память (ОП). Поэтому организация памяти оказывает большое влияние на структуру и возможности ОС.
Используемые в операционных системах алгоритмы распределения ОП многообразны. Причинами этого многообразия являются:
многоуровневая структура памяти (регистровая, оперативная, внешняя)
стремление обеспечить пользователя характеристиками, отличными от реальных (виртуальная память)
необходимость согласования распределения ОП с распределением центрального процессора
Самый простой случай управления памятью - ситуация, когда диспетчер памяти отсутствует, и в системе может быть загружена только одна программа. Именно в таком режиме работают CP/M и RT-11 SJ (Single-Job, однозадачная).
В этих системах программы загружаются с фиксированного адреса PROG_START. В CP/M это 0x100; в RT-11 - 01000. В адресах от 0 до начала программы находятся вектора прерываний, а в RT-11 - также и стек программы. В этом случае управление памятью со стороны системы состоит в том, что загрузчик проверяет, поместится ли загружаемый модуль в пространство от PROG_START до SYS_START. Если объем памяти, который использует программа, не будет меняться во время ее исполнения, то на этом все управление и заканчивается.
Однако программа может использовать динамическое управление памятью, например функцию malloc(). В этом случае уже код malloc() должен следить за тем, чтобы не залезть в системные адреса. Как правило, динамическая память начинает размещаться с адреса PROG_END = PROG_START + PROG_SIZE. PROG_SIZE в данном случае обозначает полный размер программы, то есть размер ее кода, статических данных и области, выделенной под стек.
Функция malloc() поддерживает некоторую структуру данных, следящую за тем, какие блоки памяти из уже выделенных были освобождены. При каждом новом запросе она сначала ищет блок подходящего размера в своей структуре данных и, только когда этот поиск завершится неудачей, откусывает новый блок памяти у системы. Для этого используется переменная, которая в библиотеке языка C называется brklevel. Изначально эта переменная равна PROG_END, ее значение увеличивается при выделении новых блоков, но в некоторых случаях может и уменьшаться. Это происходит, когда программа освобождает блок, который заканчивается на текущем значении brklevel.
Потребности отдельных программ в ресурсе памяти в процессе обработки могут меняться, что заранее, до запуска программы, не может быть учтено. В связи с этим необходимо распределять память динамически непосредственно в ходе вычислительного процесса, т.е. осуществлять динамическое распределение памяти.
Алгоритмы динамического упpавления памятью
Динамическое распределение памяти (его еще иногда называют управлением кучей (pool или heap)) представляет собой нетривиальную проблему. Действительно, активное использование функций malloc/free может привести к тому, что вся доступная память будет разбита на блоки маленького размера, и попытка выделения большого блока завершится неудачей, даже если сумма длин маленьких блоков намного больше требуемой. Это явление называется фрагментацией памяти. Кроме того, большое количество блоков требует длительного поиска.
В зависимости от решаемой задачи используются различные алгоритмы поиска свободных блоков памяти. Действительно, программа может требовать множество блоков одинакового размера, или нескольких фиксированных размеров. Это сильно облегчает решение проблемы фрагментации и поиска. Возможны ситуации, когда блоки освобождаются в порядке, обратном тому, в котором они выделялись. Это позволяет свести выделение памяти к стековой структуре. Возможны ситуации, когда некоторые из занятых блоков можно переместить по памяти. Так, например, функцию realloc() в ранних реализациях системы UNIX можно было использовать именно для этой цели.
В стандартных библиотеках языков высокого уровня, таких как malloc/free/realloc в C, new/dispose в Pascal и т.д., как правило, используются алгоритмы, рассчитанные на худший случай: программа требует блоки случайного размера в случайном порядке и освобождает их также случайным образом.
Возможны алгоритмы распределения памяти двух типов: когда размер блока является характеристикой самого блока, и когда его сообщают отдельно при освобождении. К первому типу относится malloc/free, ко второму - GetMem/FreeMem в Turbo Pascal. В первом случае с каждым блоком ассоциируется некоторый дескриптор, который содержит длину этого блока и еще информацию. Этот дескриптор может храниться отдельно от блока, или быть его заголовком. Иногда дескриптор состоит из двух меток - в начале блока и в его конце. Для чего это может быть полезно, будет рассказано ниже.
Обычно все свободные блоки памяти объединяются в двунаправленный связанный список. Список должен быть двунаправленным для того, чтобы из него в любой момент можно было извлечь любой блок. Впрочем, если все действия по извлечению блока производятся после поиска, то можно слегка усложнить пpоцедуpу поиска и всегда сохранять указатель на пpедыдущий блок. Это pешает пpоблему извлечения и можно огpаничиться однонапpавленным списком. Беда только в том, что многие алгоpитмы пpи объединении свободных блоков извлекают их из списка в соответствии с адpесом, поэтому для таких алгоpитмов двунапpавленный список необходим.
Поиск в списке может вестись двумя способами: до нахождения первого подходящего (first fit) блока или до блока, размер которого ближе всего к заданному - наиболее подходящего (best fit). Для нахождения наиболее подходящего мы обязаны просматривать весь список, в то время как первый подходящий может оказаться в любом месте, и среднее время поиска будет меньше.
Кроме того, в общем случае best fit увеличивает фрагментацию памяти. Действительно, если мы нашли блок с размером больше заданного, мы должны отделить «хвост» и пометить его как новый свободный блок. Понятно, что в случае best fit средний размер этого хвоста будет маленьким, и мы в итоге получим большое количество мелких блоков, которые невозможно объединить, так как пространство между ними занято.
При использовании first fit с линейным двунаправленным списком возникает специфическая проблема. Если каждый раз просматривать список с одного и того же места, то большие блоки, расположенные ближе к началу, будут чаще удаляться. Соответственно, мелкие блоки будут иметь тенденцию скапливаться в начале списка, что увеличит среднее время поиска. Простой способ борьбы с этим явлением состоит в том, чтобы просматривать список то в одном направлении, то в другом. Более радикальный и еще более простой метод состоит в том, что список делается кольцевым, и поиск каждый начинается с того места, где мы остановились в прошлый раз. В это же место добавляются освободившиеся блоки.
В ситуациях, когда размещаются блоки нескольких фиксированных размеров, алгоритмы best fit оказываются лучше. Однако библиотеки распределения памяти рассчитывают на худший случай, и в них обычно используются алгоритмы first fit.
В случае работы с блоками нескольких фиксированных размеров напрашивается такое решение: создать для каждого типоразмера свой список.
Интересный вариант этого подхода для случая, когда различные размеры являются степенями числа 2, как 512 байт, 1Кбайт, 2Кбайта и т.д., называется алгоритмом близнецов. Он состоит в том, что мы ищем блок требуемого размера в соответствующем списке. Если этот список пуст, мы берем список блоков вдвое большего размера. Получив блок большего размера, мы делим его пополам. Ненужную половину мы помещаем в соответствующий список свободных блоков. Одно из преимуществ этого метода состоит в простоте объединения блоков при их освобождении. Действительно, адрес блока-близнеца получается простым инвертированием соответствующего бита в адресе нашего блока. Нужно только проверить, свободен ли этот близнец. Если он свободен, то мы объединяем братьев в блок вдвое большего размера, и т.д.
Алгоритм близнецов значительно снижает фрагментацию памяти и резко ускоряет поиск блоков. Наиболее важным преимуществом этого подхода является то, что даже в наихудшем случае время поиска не превышает. Это делает алгоритм близнецов труднозаменимым для ситуаций, когда необходимо гарантированное время реакции - например, для задач реального времени. Часто этот алгоритм или его варианты используются для выделения памяти внутри ядра ОС. Например, функция kmalloc, используемая в ядре ОС Linux, основана именно на алгоритме близнецов.
Разработчик программы динамического распределения памяти обязан решить еще одну важную проблему, а именно - объединение свободных блоков. Наилучшим из известных универсальных алгоритмов динамического распределения памяти является алгоритм парных меток с объединением свободных блоков в двунаправленный кольцевой список и поиском по принципу first fit. Этот алгоритм обеспечивает приемлемую производительность почти для всех стратегий распределения памяти, используемых в прикладных программах. Такой алгоритм используется практически во всех реализациях стандартной библиотеки языка C и во многих других ситуациях. Другие известные алгоритмы либо просто хуже, чем этот, либо проявляют свои преимущества только в специальных случаях.
К основным недостаткам этого алгоритма относится отсутствие верхней границы времени поиска подходящего блока, что делает его неприемлемым для задач реального времени.
Некоторые системы программирования используют специальный метод освобождения динамической памяти, называемый сборкой мусора. Этот метод состоит в том, что ненужные блоки памяти не освобождаются явным образом. Вместо этого используется некоторый более или менее изощренный алгоритм, следящий за тем, какие блоки еще нужны, а какие - уже нет.
Самый простой метод- отличать используемые блоки от ненужных - считать, что блок, на который есть ссылка, нужен, а блок, на который ни одной ссылки не осталось - не нужен. Для этого к каждому блоку присоединяют дескриптор, в котором подсчитывают количество ссылок на него. Каждая передача указателя на этот блок приводит к увеличению счетчика ссылок на 1, а каждое уничтожение объекта, содержавшего указатель - к уменьшению.
Все остальные методы сборки мусора так или иначе сводятся к поддержанию базы данных о том, какие объекты на кого ссылаются. Использование такой техники возможно практически только в интерпретируемых языках типа Lisp или Prolog, где с каждой операцией можно ассоциировать неограниченно большое количество действий.
Многозадачная или многопрограммная ОС также должны использовать тот или иной алгоритм размещения памяти. Такие алгоритмы могут быть похожи на работу malloc. Однако режим работы ОС может вносить существенные упрощения в алгоритм.
Так, например, пpоцедуpа управления памятью MS DOS рассчитана на случай, когда программы выгружаются из памяти только в порядке, обратном тому, в каком они туда загружались. Это позволяет свести управление памятью к стековой дисциплине.
Каждой программе в MS DOS отводится блок памяти. С каждым таким блоком ассоциирован дескриптор, называемый MCB - Memory Control Block. Этот дескриптор содержит размер блока, идентификатор программы, которой принадлежит этот блок и признак того, является ли данный блок последним в цепочке. Нужно отметить, что программе всегда принадлежит несколько блоков, но это уже несущественные детали. Другая малосущественная деталь та, что размер сегментов и их адреса отсчитываются в параграфах размером 16 байт. После запуска.com-файл получает сегмент размером 64К, а.exe - всю доступную память. Обычно.exe-модули сразу после запуска освобождают ненужную им память и устанавливают brklevel на конец своего сегмента, а потом увеличивают brklevel и наращивают сегмент по мере необходимости. Естественно, что наращивать сегмент можно только за счет следующего за ним в цепочке MCB, и MS DOS разрешит делать это только в случае, если этот сегмент не принадлежит никакой программе.
При запуске программы DOS берет последний сегмент в цепочке, и загружает туда программу, если этот сегмент достаточно велик. Если он недостаточно велик, DOS «говорит» Not enough memory и отказывается загружать программу.
При завершении программы DOS освобождает все блоки, принадлежавшие программе. При этом соседние блоки объединяются. Пока программы, действительно, завершаются в порядке, обратном тому, в котором они запускались, - все вполне нормально. Другое дело, что в реальной жизни возможны отклонения от этой схемы.
Например, неявно предполагается, что TSR-программы (Terminate, but Stay Resident) никогда не пытаются завершиться. Другой пример - отладчики обычно загружают программу в обход обычной DOS-овской функции LOAD & EXECUTE, а при завершении отлаживаемой программы сами освобождают память из-под нее.
В системах с динамической сборкой первые две проблемы не так остры, потому что память выделяется и освобождается небольшими кусочками, по блоку на каждый объектный модуль, поэтому код программы обычно не занимает непрерывного пространства. Соответственно, такие системы часто разрешают и данным программы занимать несмежные области памяти.
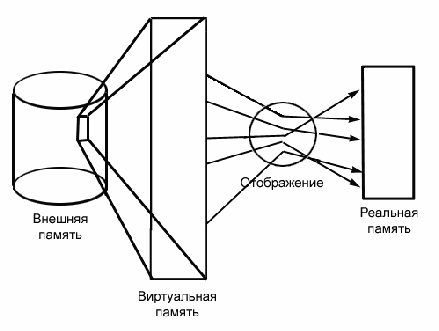
Для достижения гибкого динамического распределения памяти, устранения ее фрагментации, а также создания значительных удобств для программирования в современных ОС широко используется виртуальная память. При этом на всех этапах подготовки программ, включая загрузку в оперативную память, программа представляется в виртуальных адресах и лишь при самом исполнении машиной команды производится преобразование виртуальных адресов в адреса действующей памяти (в так называемые физические адреса). Это преобразование составляет содержание динамического распределения памяти.
Объем виртуального адресного пространства может даже превосходить всю доступную реальную память на ЭВМ. Содержимое виртуальной памяти, неиспользуемой программой, хранится на некотором внешнем устройстве (внешней памяти). По необходимости части этой виртуальной памяти отображаются в реальную память. Ни о внешней памяти, ни о ее отображении в реальную память программа ничего не знает. Она написана так, как будто бы виртуальная память существует в действительности (рис. 2.).
Рис.2. Основная концепция виртуальной памяти
При страничной организации основная память делится на блоки фиксированного размера, обычно называемые рамка страниц. Каждая программа пользователя делится на блоки сответствующего размера, называемые страницами. Страницы организуются в логическом адресном пространстве, а рамки cтраниц - в физическом. Поскольку страницы и рамки страниц имеют различные идентификаторы, возникают интересные ситуации, касающиеся взаимосвязи между логическим адресным пространством (ЛАП) и физическим адресным пространством ФАП).
1. ЛАП < ФАП. В этом случае основной акцент делается на повышение эффективности использования памяти.
2. ЛАП = ФАП. Страничная организация служит не только для увеличения эффективности использования памяти, но и для расширения возможности разделенного использования процедур (т.е. несколькими пользователями). Возможно использование эффективного оверлейного механизма, реализованного аппаратно.
3. ЛАП > ФАП. Этот случай предполагает виртуальную память и дает наибольшие преимущества.
Мы будем рассматривать управление страницами применительно к последнему случаю. Выбор между случаями 1 и 2 обычно находится в зависимости от структуры Устройства Управления Памятью (УУП) и задач проектировщика операционной системы. Пользователь, располагая ЛАП из m страниц, будет иметь k страниц, отведенных под интерпретатор, и m - k страниц рабочего пространства. Описанный подход эффективен для системы с разделением времени.
Идентификация. Страницы и рамки страниц с набжают числовыми идентификаторами, устанавливаемыми по следующему правилу.
Пусть p есть размер страницы в словах (например, 512).
Пусть т есть размер основной памяти в словах, такой, что m=n*p по модулю 1024 есть 0; р по модулю 2К есть 0 и i*p=j*1024. Таким образом, основная память состоит из участков по 1К слов в каждом. Кроме этого, размер страницы есть степень числа 2, а 1К памяти содержит четное число страниц. Набор целых чисел 0, 1, 2,...,п-1 соответствует идентификаторам страничных рамок.
Пусть М есть размер программы пользователя в словах. Для размещения этой программы в памяти необходимо N страниц, так что М=N*p. Набор целых чисел от 0 до п-1 соответствует идентификаторам страниц пользователя. Заметим, что требование равенства нулю m по модулю р не является обязательным. Это означает, что программа пользователя не должна заполнять целиком все страницы. Последняя страница может быть заполнена лишь частично.
Используя двоичную арифметику, - представление страницы степенью числа 2 легко реализуемо. Фактически в большинстве машин имеются команды сдвига, делающие генерацию виртуального адреса очень простой операцией. Требование задания М кратным 1К является результатом стандартизации. В последнее время принято считать, что размер 8К, 16К и даже 64К более предпочтителен.
Конструкция виртуального адреса. Виртуальный адрес - это адрес логического пространства процесса пользователя (обычно для случая ЛАП >ФАП). Все ссылки к логическому пространству должны быть преобразованы в физический адрес основной памяти. Для этого системе необходимы идентификатор рамки страницы и смещение внутри нее. Система должна преобразовать виртуальный адрес в физический. Каждый виртуальный адрес есть пара (р, i), где р - номер страницы процесса пользователя, а i-индекс страницы (такой, что i
Предположим, что машина имеет 16-бит слово, позволяющее ей адресоваться к 64К слов. Если размер страницы составит 512 слов, то логическое адресное пространство будет состоять из 128 страниц. Для идентификатора р необходимо 7 бит, а для индекса 9 бит. Полное 16-бит слово будет иметь вид
Идентификатор - страницы
Индекс - слова
Отметим, что случай ЛАП<ФАП возможен, если устройство управления памятью обеспечивает размер слова, больший чем 18 бит. На ЭВМ серии PDP-11/70 ЛАП каждого пользователя ограничено 64К байт, в то время как УУП поддерживает 128К слов. В ЭВМ серии VAX-11/780 фирмы DEC адресное пространство каждого пользователя составляет 232, а максимальный физический размер основной памяти может достигать 16М байт. В ЭВМ серии VAX-11/780 используется 32-бит слово, имеющее следующую конструкцию:
31
30
Вид виртуальной
Страницы
Байт в
странице
где биты 31 и 30 имеют специальное назначение для;VAX/VMS;биты 29 - 9 адресуются к одной из 220страниц;биты 7 - 0 выбирают один из 512 байт в странице.
На ЭВМ, имеющей 16-бит размер слова, большой виртуальный адрес может быть составлен из двух слов. Он может иметь, например, такой вид:
Номер
страницы
Байт в
странице
Роль таблицы страниц. Одним из достоинств страничной организации является динамическое распределение страниц пользователя в любом месте памяти. Так, страница Р процесса
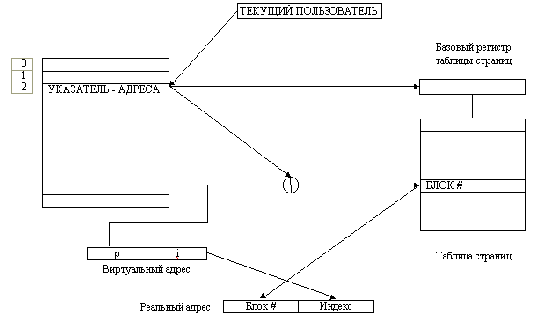
Рис. 3.Отображение страницы на основную память.
Виртуальный адрес = (р,i). Физический адрес - x = размер страницы + i. Отрицательное значение идентификатора рамки страницы указывает на то, что страница в данный момент отсутствует в памяти
пользователя может в некоторый момент занимать страничную рамку р в физической памяти. Поскольку у каждого из пользователей имеется свой набор страниц, каждой программе необходима карта, отображающая взаимосвязь между страницами и рамками страниц. На рис. 1 виртуальный адрес (p, i) преобразовывается в физический, поиском в таблице страниц идентификатора х для рамки страницы. Реальный адрес образуется умножением х на размер страницы и прибавлением к полученному результату индекса i.
Важно отметить, что эти операции осуществляются УУП согласованно с программой пользователя. Для этого копия таблицы страниц процесса должна быть загружена в УУП.
Рис. 3. Обобщенная процедура страничного обмена. Блок # - это адрес рамки страницы в основной памяти (поэтому умножения на размер страницы не требуется).
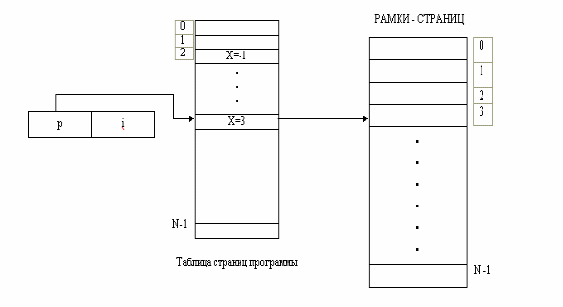
Например, предположим, что УУП располагает пространством для 16 карт памяти, а каждая карта памяти содержит поля (элементы) для 64 страниц по 512 слов в каждой. Карта с номером 0 всегда принадлежит ядру операционной системы. Такой подход не может быть реализован для систем с большим объемом виртуальной памяти, так как стоимость УУП будет чрезмерно большой. В этом случае карта остается в основной памяти, а УУП управляет текущей картой пользователя с помощью указателей. На рис.2 приведена структура, соответствующая такой схеме.
По этой схеме УУП поддерживает список адресов таблиц для n пользователей. Аппаратно реализованный регистр служит для указания текущего пользователя, т.е. пользователя, чья таблица страниц является в настоящий момент активной. Элемент таблицы, содержащий карту пользователя (в УУП), загружается в аппаратный регистр базы таблицы страниц. Каждый адрес памяти содержит идентификатор страницы и индекс. Идентификатор страницы в комбинации с содержимым базового регистра таблицы страниц указывает на элемент таблицы страниц. Содержимым этого элемента является адрес рамки страницы в памяти. Добавляя индекс к адресу рамки страницы, мы получаем физический адрес.
Отметим, что при такой схеме каждая ссылка таблицы страниц требует дополнительного доступа к памяти для извлечения адреса рамки страницы. В предыдущем случае все вычисления основывались на использовании аппаратных регистров УУП. Таким образом, применение виртуальной памяти большого объема может привести к временным задержкам в системе и увеличению общего времени работы программы. Разработчик системы должен учитывать эти факторы при выборе способа управления памятью на этапе проектирования системы.
Контрольные биты страниц. С каждым элементом таблицы связывается набор контрольных битов. Эти биты служат для указания стратегии управления страницами. Количество и тип этих битов определяются примененным УУП. Биты, приведенные ниже, характерны для аппаратной части большинства систем.
1. БИТ-ПРИСУТСТВИЯ указывает, находится ли страница в данный момент в основной памяти.
2. БИТ(Ы)-АКТИВНОСТИ указывает на использование за последнее время данной страницы процедурами страничного обмена.
3. БИТ-ИЗМЕНЕНИЯ указывает на то, что содержимое страницы памяти изменялось (или не изменялось) с момента ее загрузки в память.
Бит присутствия анализируется при каждой адресной ссылке программы пользователя. Равенство его нулю означает, что страница была удалена из памяти. Бит изменения определяет необходимость записи страницы на диск при ее замене в памяти. Единичное его значение означает, что в содержимом страницы были сделаны изменения, и, следовательно, она должна быть записана на диск. (Нулевое значение предполагает использование прежней копии.) В системах, в которых страницы инструкций (в противоположность страницам данных) являются реентерабельными, бит изменения никогда не устанавливается.
2. Разработка алгоритма управления оперативной памятью
Ниже приведён алгоритм управления оперативной памятью в системе Linux. В основе всего лежат страницы памяти. В ядре они описываются структурой mem_map_t.
typedef struct page {
/* these must be first (free area handling) */
struct page *next;
struct page *prev;
struct inode *inode;
unsigned long offset;
struct page *next_hash;
atomic_t count;
unsigned long flags; /* atomic flags, some possibly updated asynchronously */
struct wait_queue *wait;
struct page **pprev_hash;
struct buffer_head * buffers;
} mem_map_t;
В системе применяется множество ссылок, которые в свою очередь используются для управления ОП. Одна страница может находиться в разных списках, например и в списке страниц в страничном кеше и в списке страниц относящихся к отображенному в память файлу (inode).В структуре, описывающей последний, можно найти и обратную ссылку, что очень удобно.
Все страницы адресуются глобальным указателем mem_map
mem_map_t * mem_map
Адресация происходит наиболее интерестно. Если раньше (в ранних версиях ядра) в структуре page было отдельное поле указывающее на физический адрес (map_nr), то теперь он вычисляется. Алгоритм вычисления можно обнаружить в следующей функции ядра.
static inline unsigned long page_address(struct page * page)
{
return PAGE_OFFSET + PAGE_SIZE * (page - mem_map);
}
Свободные страницы хранятся в особой структуре free_area
static struct free_area_struct free_area[NR_MEM_TYPES][NR_MEM_LISTS];
где первое поле отвечает за тип области: Ядра, Пользователя, DMA и т.д. И обрабатываются по очень интересному алгоритму.
Страницы делятся на свободные непрерывные области размера 2 в степени x умноженной на размер страницы ((2^x)*PAGE_SIZE). Области одного размера лежат в одной области массива.
Таблица 1.
Свободные Страницы размера PAGE_SIZE*4 --->
список свободных областей
Свободные Страницы размера PAGE_SIZE*2 --->
список свободных областей
Свободные Страницы размера PAGE_SIZE --->
список свободных областей
Выделение стараницы выполняется функцией get_free_pages(order). Она выделяет страницы составляющие область размера PAGE_SIZE*(2^order). Делается это следующим образом: ищется область соответствующего размера или больше. Если есть только область большего размера, то она делится на несколько маленьких и берется нужный кусок. Если свободных страниц недостаточно, то некоторые будут сброшены в область подкачки и процесс выделения начнется снова. Возвращает страницу функция free_pages(struct page, order). Высвобождает страницы, начинающиеся с page размера PAGE_SIZE*(2^order). Область возвращается в массив свободных областей в соответствующую позицию и после этого происходит попытка объединить несколько областей для создания одной большего размера.
Отсутствие страницы в памяти обрабатываются ядром особо. Страница может или вообще отсутствовать или находиться в области подкачки.
Весь процесс работает с виртуальными адресами, а не с физическими. Преобразование происходит посредством вычислений, используя таблицы дескрипторов, и каталоги таблиц. Linux поддерживает 3 уровня таблиц: каталог таблиц первого уровня (PGD - Page Table Directory),каталог таблиц второго уровня (PMD - Medium Page Table Diractory), и, таблица дескрипторов (PTE - Page Table Entry). Конкретным процессором могут поддерживаться не все уровни, но запас позволяет поддерживать больше возможных архитектур (Intel имеет 2 уровня таблиц, а Alpha - целых 3). Преобразование виртуального адреса в физический происходит соответственно в 3 этапа. Берется указатель PGD, имеющийся в структуре описывающий каждый процесс, преобразуется в указатель записи PMD, а последний преобразуется в указатель в таблице дескрипторов PTE. И, наконец, к реальному адресу, указывающему на начало страницы прибавляют смещение от ее начала. Хороший пример подобной процедуры можно посмотреть в функции ядра partial_clear:
page_dir = pgd_offset(vma->vm_mm, address);
if (pgd_none(*page_dir))
return;
if (pgd_bad(*page_dir)) {
printk("bad page table directory entry %p:[%lx]\n", page_dir, pgd_val(*page_dir));
pgd_clear(page_dir);
return;
}
page_middle = pmd_offset(page_dir, address);
if (pmd_none(*page_middle))
return;
if (pmd_bad(*page_middle)) {
printk("bad page table directory entry %p:[%lx]\n", page_dir, pgd_val(*page_dir));
pmd_clear(page_middle);
return;
}
page_table = pte_offset(page_middle, address);
Все данные об используемой процессом памяти помещаются в структуре: mm_struct
struct mm_struct {
struct vm_area_struct *mmap; /* Список отображенных областей */
struct vm_area_struct *mmap_avl; /* Те же области но уже в виде дерева
для более быстрого поиска */
struct vm_area_struct *mmap_cache; /* Последняя найденная область */
pgd_t * pgd; /*Каталог таблиц*/
atomic_t count;
int map_count; /* Количество областей*/
struct semaphore mmap_sem;
unsigned long context;
unsigned long start_code, end_code, start_data, end_data;
unsigned long start_brk, brk, start_stack;
unsigned long arg_start, arg_end, env_start, env_end;
unsigned long rss, total_vm, locked_vm;
unsigned long def_flags;
unsigned long cpu_vm_mask;
unsigned long swap_cnt; /* количество страниц для свопинга при следующем проходе */
unsigned long swap_address;
/*
* Это архитектурно-зависимый указатель. Переносимая часть Linux
ничего не знает о сегментах. */
void * segments;
};
Замечаем, что помимо вполне понятных указателей на начало данных (start_code, end_code...) кода и стека есть указатели на данные отображенных файлов (mmap).
На уровне процесса работа может вестись как со страницами напрямую, так и через абстрактную структуру vm_area_struct
struct vm_area_struct {
struct mm_struct * vm_mm; /* параметры области виртуальной памяти */
unsigned long vm_start;
unsigned long vm_end;
/* Связянный список областей задачи отсортированный по адресам */
struct vm_area_struct *vm_next;
pgprot_t vm_page_prot;
unsigned short vm_flags;
/* AVL-дерево областей, для ускоренного поиска, сортировка по адресам */
short vm_avl_height;
struct vm_area_struct * vm_avl_left;
struct vm_area_struct * vm_avl_right;
/* Для областей используемых при отображении файлов или при работе
с разделяемой памяти, иначе эта часть структуры не используется */
struct vm_area_struct *vm_next_share;
struct vm_area_struct **vm_pprev_share;
struct vm_operations_struct * vm_ops; /*операции над областью */
unsigned long vm_offset;
struct file * vm_file;
unsigned long vm_pte; /* разделяемая память */
};
struct vm_operations_struct {
void (*open)(struct vm_area_struct * area);
void (*close)(struct vm_area_struct * area);
void (*unmap)(struct vm_area_struct *area, unsigned long, size_t);
void (*protect)(struct vm_area_struct *area, unsigned long, size_t, unsigned int newprot);
int (*sync)(struct vm_area_struct *area, unsigned long, size_t, unsigned int flags);
void (*advise)(struct vm_area_struct *area, unsigned long, size_t, unsigned int advise);
unsigned long (*nopage)(struct vm_area_struct * area, unsigned long address, int write_access);
unsigned long (*wppage)(struct vm_area_struct * area, unsigned long address,
unsigned long page);
int (*swapout)(struct vm_area_struct *, struct page *);
pte_t (*swapin)(struct vm_area_struct *, unsigned long, unsigned long);
};
Данная структура возникла из идеи виртуальной файловой системы, поэтому все операции над виртуальными областями абстрактны и могут быть специфичными для разных типов памяти, например при отображении файлов операции чтения одни, а при отображении памяти (через файл /dev/mem) совершенно другие. Первоначально vm_area_struct появилась для обеспечения нужд отображения, но постепенно распространяется и для других целей.
Что делать, когда требуется получить новую область памяти. Есть целых 3 способа.
get_free_page()
kmalloc - Простенькая (по возможностям) процедура с большими ограничениями по выделению новых областей и по их размеру.
vmalloc - Мощная процедура, работающая с виртуальной памятью, может выделять большие объемы памяти.
С каждой из двух процедур в ядре связаны еще по списку свободных/занятых областей, что еще больше усложняет понимание работы с памятью. (vmlist для vmalloc, kmem_cash для kmalloc)
Добавлена поддержка новой архитектуры памяти NUMA. В противовес классической UMA память делится на зоны с разным временем доступа к каждой из них. Это очень полезно и для кластерных решений. В связи с этим появились новые обертки на функции, новые структуры и найти суть стало еще сложнее. Появилась также поддержка памяти до 64Гб.
Ранее для всех файловых систем был один generic_file_read и generic_file_mmap в связи с тотальным засасыванием всего подряд в память при чтении (различия делались уже только на уровне inode->readpage).
Вывод.
В процессе выполнения курсовой работы, было выполнено изучение параметров, характеристик оперативной памяти. Также были изучены виды, типы, структуры и алгоритмы управления оперативной памятью. Далее был предоставлен пример работы операционной системы Linux с оперативной памятью.
Список используемой литературы
1. Рихтер Джеффри "Linux для профессионалов", С-П. Русская редакция 1998.
2. Хендерсон К. "Руководство разработчика баз данных"
3. Г. Майерс "Надежность ПО" Мир, М., 1980

Нравится материал? Поддержи автора!
Ещё документы из категории информатика:
Чтобы скачать документ, порекомендуйте, пожалуйста, его своим друзьям в любой соц. сети.
После чего кнопка «СКАЧАТЬ» станет доступной!
Кнопочки находятся чуть ниже. Спасибо!
Кнопки:
Скачать документ