Анализ эффективности MPI-программ
 Оглавление
Оглавление
1.Введение
Сегодня невозможно представить себе эффективную организацию работы без применения компьютеров в таких областях, как планирование и управление производством, проектирование и разработка сложных технических устройств, издательская деятельность, образование - словом, во всех областях, где возникает необходимость в обработке больших объемов информации. Однако наиболее важным по-прежнему остается использование их в том направлении, для которого они собственно и создавались, а именно, для решения больших задач, требующих выполнения громадных объемов вычислений. Такие задачи возникли в середине прошлого века в связи с развитием атомной энергетики, авиастроения, ракетно-космических технологий и ряда других областей науки и техники.
В наше время круг задач, требующих для своего решения применения мощных вычислительных ресурсов, еще более расширился. Это связано с тем, что произошли фундаментальные изменения в самой организации научных исследований. Вследствие широкого внедрения вычислительной техники значительно усилилось направление численного моделирования и численного эксперимента. Численное моделирование, заполняя промежуток между физическими экспериментами и аналитическими подходами, позволило изучать явления, которые являются либо слишком сложными для исследования аналитическими методами, либо слишком дорогостоящими или опасными для экспериментального изучения. При этом численный эксперимент позволил значительно удешевить процесс научного и технологического поиска. Стало возможным моделировать в реальном времени процессы интенсивных физико-химических и ядерных реакций, глобальные атмосферные процессы, процессы экономического и промышленного развития регионов и т.д. Очевидно, что решение таких масштабных задач требует значительных вычислительных ресурсов[12].
Вычислительное направление применения компьютеров всегда оставалось основным двигателем прогресса в компьютерных технологиях. Не удивительно поэтому, что в качестве основной характеристики компьютеров используется такой показатель, как производительность - величина, показывающая, какое количество арифметических операций он может выполнить за единицу времени. Именно этот показатель с наибольшей очевидностью демонстрирует масштабы прогресса, достигнутого в компьютерных технологиях.
В настоящее время главным направлением повышения производительности ЭВМ является создание многопроцессорных систем с распределенной памятью. Создание прикладных программ для подобных распределенных систем наталкивается на ряд серьезных трудностей. Разработка параллельной программы требует выбора или создания подходящего вычислительного метода. При этом для достижения требуемой эффективности приходится многократно проходить путь от спецификации алгоритма к программе на языке программирования, который для параллельных вычислительных систем оказывается гораздо более сложным, чем для последовательных.
При переходе от одного процессора к нескольким резко возрастает сложность программирования. И многие традиционные подходы здесь уже не работают. Причём если на мультипроцессорной системе достаточно правильно распределить вычисления, то в случае распределённой системы необходимо ещё распределить данные, и самое главное, нужно, чтобы распределение данных и вычислений было согласованным.
Одной из ключевых проблем является проблема эффективности компьютерной программы. Важно видеть, какой эффект дает распараллеливание нашей программы и что можно сделать, чтобы максимизировать этот эффект.
Эффективность выполнения параллельных программ на многопроцессорных ЭВМ с распределенной памятью определяется следующими основными факторами:
степенью распараллеливания программы - долей параллельных вычислений в общем объеме вычислений;
равномерностью загрузки процессоров во время выполнения параллельных вычислений;
временем, необходимым для выполнения межпроцессорных обменов;
степенью совмещения межпроцессорных обменов с вычислениями;
эффективностью выполнения вычислений на каждом процессоре (а она может варьироваться значительно в зависимости от степени использования кэша).
Методы и средства отладки производительности параллельной программы существенно зависят от той модели, в рамках которой разрабатывается параллельная программа.
2. Обзор существующих моделей параллельного программирования
Для организации доступа к данным на многопроцессорных ЭВМ требуется взаимодействие между её процессорами. Это взаимодействие может происходить либо через общую память, либо через механизм передачи сообщений – две основные модели параллельного выполнения программы. Однако эти модели являются довольно низкоуровневыми. Поэтому главным недостатком выбора одной из них в качестве модели программирования является то, что такая модель непривычна и неудобна для программистов, разрабатывающих вычислительные программы.
Можно отметить системы автоматического распараллеливания, которые вполне успешно использовались на мультипроцессорах. А использование этих систем на распределённых системах существенно затруднено тем, что
Во-первых, поскольку взаимодействие процессоров через коммуникационную систему требует значительного времени (латентность – время самого простого взаимодействия - велика по сравнению со временем выполнения одной машинной команды), то вычислительная работа должна распределяться между процессорами крупными порциями.
Во-вторых, в отличие от многопроцессорных ЭВМ с общей памятью, на системах с распределенной памятью необходимо произвести не только распределение вычислений, но и распределение данных, а также обеспечить на каждом процессоре доступ к удаленным данным - данным, расположенным на других процессорах. Для обеспечения эффективного доступа к удаленным данным требуется производить анализ индексных выражений не только внутри одного цикла, но и между разными циклами. К тому же, недостаточно просто обнаруживать факт наличия зависимости по данным, а требуется определить точно тот сегмент данных, который должен быть переслан с одного процессора на другой.
В третьих, распределение вычислений и данных должно быть произведено согласованно.
Несогласованность распределения вычислений и данных приведет, вероятнее всего, к тому, что параллельная программа будет выполняться гораздо медленнее последовательной. Согласованное распределение вычислений и данных требует тщательного анализа всей программы, и любая неточность анализа может привести к катастрофическому замедлению выполнения программы.
В настоящее время существуют следующие модели программирования:
Модель передачи сообщений. MPI.[1]
В модели передачи сообщений параллельная программа представляет собой множество процессов, каждый из которых имеет собственное локальное адресное пространство. Взаимодействие процессов - обмен данными и синхронизация - осуществляется посредством передачи сообщений. Обобщение и стандартизация различных библиотек передачи сообщений привели в 1993 году к разработке стандарта MPI (Message Passing Interface). Его широкое внедрение в последующие годы обеспечило коренной перелом в решении проблемы переносимости параллельных программ, разрабатываемых в рамках разных подходов, использующих модель передачи сообщений в качестве модели выполнения.
В числе основных достоинств MPI по сравнению с интерфейсами других коммуникационных библиотек обычно называют следующие его возможности:
Возможность использования в языках Фортран, Си, Си++;
Предоставление возможностей для совмещения обменов сообщениями и вычислений;
Предоставление режимов передачи сообщений, позволяющих избежать излишнего копирования информации для буферизации;
Широкий набор коллективных операций (например, широковещательная рассылка информации, сбор информации с разных процессоров), допускающих гораздо более эффективную реализацию, чем использование соответствующей последовательности пересылок точка-точка;
Широкий набор редукционных операций (например, суммирование расположенных на разных процессорах данных, или нахождение их максимальных или минимальных значений), не только упрощающих работу программиста, но и допускающих гораздо более эффективную реализацию, чем это может сделать прикладной программист, не имеющий информации о характеристиках коммуникационной системы;
Удобные средства именования адресатов сообщений, упрощающие разработку стандартных программ или разделение программы на функциональные блоки;
Возможность задания типа передаваемой информации, что позволяет обеспечить ее автоматическое преобразование в случае различий в представлении данных на разных узлах системы.
Однако разработчики MPI подвергаются и суровой критике за то, что интерфейс получился слишком громоздким и сложным для прикладного программиста. Интерфейс оказался сложным и для реализации, в итоге, в настоящее время практически не существует реализаций MPI, в которых в полной мере обеспечивается совмещение обменов с вычислениями.
Появившийся в 1997 проект стандарта MPI-2 [2] выглядит еще более громоздким и неподъемным для полной реализации. Он предусматривает развитие в следующих направлениях:
Динамическое создание и уничтожение процессов;
Односторонние коммуникации и средства синхронизации для организации взаимодействия процессов через общую память (для эффективной работы на системах с непосредственным доступом процессоров к памяти других процессоров);
Параллельные операции ввода-вывода (для эффективного использования существующих возможностей параллельного доступа многих процессоров к различным дисковым устройствам).
Вкратце о других моделях:
Модель неструктурированных нитей. Программа представляется как совокупность нитей (threads), способных выполняться параллельно и имеющих общее адресное пространство. Имеющиеся средства синхронизации нитей позволяют организовывать доступ к общим ресурсам. Многие системы программирования поддерживают эту модель: Win32 threads, POSIX threads, Java threads.
Модель параллелизма по данным. Основным её представителем является язык HPF [3]. В этой модели программист самостоятельно распределяет данные последовательной программы по процессорам. Далее последовательная программа преобразуется компилятором в параллельную, выполняющуюся либо в модели передачи сообщений, либо в модели с общей памятью. При этом каждый процессор производит вычисления только над теми данными, которые на него распределены.
Модель параллелизма по управлению. Эта модель возникла в применении к мультипроцессорам. Вместо терминов нитей предлагалось использовать специальные конструкции – параллельные циклы и параллельные секции. Создание, уничтожение нитей, распределение на них витков параллельных циклов или параллельных секций – всё это брал на себя компилятор. Стандартом для этой модели сейчас является интерфейс OpenMP [4].
Гибридная модель параллелизма по управлению с передачей сообщений. Программа представляет собой систему взаимодействующих MPI – процессов, каждый из которых программируется на OpenMP.
Модель параллелизма по данным и управлению – DVM (Distributed Virtual Machine, Distributed Virtual Memory) [5]. Эта модель была разработана в Институте прикладной математики им. М. В. Келдыша РАН.
3. Обзор средств отладки эффективности MPI-программ
При анализе MPI-программ могут возникать различные сложные ситуации, для анализа которых можно применить специально разработанные инструменты. Эти программы могут помочь в решении возникающих проблем. Большинство таких инструментов объединяет то, что они во время выполнения программы производят сбор информацию в трассу (описание событий), а затем предоставляют различные средства анализа и визуализации полученных данных.
Обычно для целей трассировки в исследуемую программу встраиваются "профилировочные" вызовы, которые фиксируют наступление определенных событий или продолжительность интервалов, и фиксируют эту информацию в журнале трассировки, передают ее online-анализатору или просто модифицируют собираемую статистику.
Можно выделить два основных подхода к анализу производительности:
A. "Трассировка + Визуализация". Данный подход подразумевает два этапа:
A1. Во время исполнения программы собирается "трасса", т.е. журнал о ходе работы программы.
A2. Затем полученная трасса просматривается и анализируется.
B. "Online-анализ". Поведение программы анализируется непосредственно в ходе ее выполнения.
Semi-automatic Preparation
executable
User program
Trace files
Automatic Analysis
Рис.1 Схема А. “Трассировка + Визуализация”.
3.1 Общие проблемы всех средств трассировки
Формат трасс не унифицирован и обычно ориентирован на конкретную библиотеку передачи сообщений.
Сбор информации - слабые возможности настройки фильтров событий (какие события и какую информацию включать в трассы). Нет возможности варьировать объем трассы.
Не учитывается эффекта замера - средство трассировки достаточно сильно изменяет поведение программы.
Проблемы визуализации.
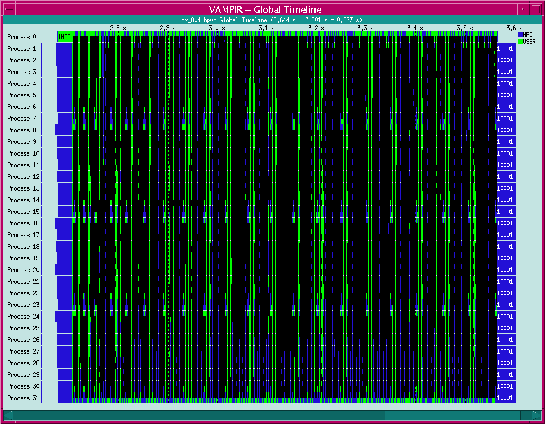
Что показывать? Какая информация интересна и полезна для отладки эффективности MPI программы.
Как показывать? Рис.2 . Надо проводить обобщение собираемой информации. Просто вид всех событий может быть неинформативен.
Когда показывать? Важно показывать то, что полезно в данный момент для отладки эффективности, чтобы не загромождать пользователя излишней информацией.
Рис.2 VAMPIR.
3.2 Обзор основных средств отладки
Ниже будут кратко описаны некоторые основные средства отладки MPI-программ:
AIMS -инструментарий, библиотека мониторинга и средства анализа
MPE -библиотека сохранения Log-файлов средство визуализации Nupshot
Pablo - библиотека мониторинга и средства анализа
Paradyn – динамический инструментарий и ран тайм библиотека
SvPablo – интегрированный инструментарий, библиотека мониторинга, средства анализа
VAMPIRtrace - библиотека мониторинга and VAMPIR – средство визуализации
3.2.1 AIMS - Automated Instrumentation and Monitoring System
Место разработки:
Некоммерческий продукт, разрабатывается в NASA Ames Research Center в рамках программы High Performance Computing and Communication Program.
Тип
Тип А (трассировка + визуализация)
Языки/Библиотеки
Fortran 77, HPF, С. Библиотеки передачи сообщений: MPI,PVM,NX.
Платформы
IBM RS/6000 SP, рабочие станции Sun и SGI, Cray T3D/T3E.
Функциональность трассировки
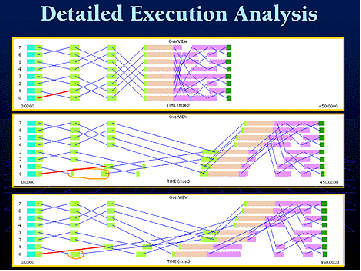
Сбор трасс. Автоматизированное изменение исходного кода программы путем вставки специальных вызовов. Параллельно со сбором трассы создается файл со статической информацией.
Уровни детализации. Подпрограммы, вызовы процедур, процедуры различного типа (процедуры ввода-вывода, MPI процедуры т.п.)
Формат трасс. Формат описан в[7]. Ориентирован на передачу сообщений.
Тип трассировки. События, статистика (может собираться без полной трассы).
Визуализация
Процессы - параллельные линии. События изображаются точками на этих линиях. Особым образом изображаются накладные расходы: времена ожидания, блокировка. Есть возможность "проигрывания" трасс.
Время - реальное (астрономическое)
Связь линий процессов линиями, обозначающими взаимодействия (передача сообщений, глобальные операции).
Диаграммы взаимодействия процессов, временные срезы, история вызовов и трассируемых блоков.
Поддерживается связь с исходным кодом.
Статистика
Суммарное время по замеряемым инструкциям или типам инструкций и количество срабатываний.
Рис.3 AIMS. Результат подробного анализа запуска.
URL
http://www.pallas.de/pages/vampir.htm
Где разрабатывается?
Коммерческий продукт, разработка компании Pallas (Германия).
Версии
VAMPIR 4.0 (X Window), VAMPIRtrace 4.0
Тип
Тип А (трассировка + визуализация). VampirTrace - система генерации трасс (A1), Vampir - система визуализации (A2).
Языки/библиотеки
Языки - Fortran, C; передача сообщений в рамках MPI.
Платформы
DEC Alpha (OSF/1)
Fujitsu VP 300/700
Hitachi SR2201
IBM RS/6000, SP
Intel Paragon
NEC SX-4
SGI Origin, PowerChallenge (IRIX 6)
Sun SPARC
Intel x86 (Solaris 2.5)
Функциональность трассировки.
Сбор трасс. Линковка с VampirTrace - прослойкой между MPI и пользовательской программой. Уровни детализации. Cлабые вохможности настройки уровня детализации - только по подпрограммам. Возможна установка точек начала/конца трассировки. Тип трассировки. Только события (статистика собирается на этапе анализа трасс).
Визуализация
Процессы - параллельные линии, события - точки на них.
Взаимодействия. Связь линий процессов, матрицы объемов и количества пересылок
Другие объекты. Круговые диаграммы и статистические гистограммы.
Поддерживается связь с исходным кодом.
Статистика
Cуммарное время по замеряемым инструкциям или типам инструкций и количеству срабатываний; отображается на круговых диаграммах и гистограммах.
Рис.4. VAMPIR 4.0
Jumpshot
URL
http://www-unix.mcs.anl.gov/mpi/www/www1/Jumpshot.html
Где разрабатывается?
Некоммерческое средство, разработано в Аргоннской национальной лаборатории. Распространяется вместе с пакетом MPICH.
Версия
Jumpshot 1.0 (требуется Java 1.1 или выше)
Тип
A2 (визуализация трасс)
Языки/библиотеки
Передача сообщений: MPI.
Платформа
Сбор трасс - любые платформы, где работает MPICH. Визуализация - Java.
Функциональность трассировки
Сбор трасс. Для получения трассы программу необходимо откомпилировать с профилировочной версией библиотеки MPICH. Формат трасс. CLOG. Тип трасс. События
Визуализация
Процессы - параллельные линии, цветом изображается тип функции. Взаимодействия. Связь линий процессов. Другие объекты. Объемы пересылок по времени, гистограммы накладных расходов по времени.
Статистика
Суммарные времена работы различных типов процедур.
Разное
jumpshot входит в состав MPICH начиная с версии 1.1.1 и заменяет собой Tcl/Tk-программы upshot/nupshot, входившие в состав MPICH более ранних версий.
Pablo Performance Analysis Toolkit Software
Пакет состоит из набора средств:
SvPablo - визуализатор статистической информации (X Window).
SDDF - библиотека для записи трасс и набор средств для работы с SDDF файлами
Trace Library and Extensions - библиотека для трассировки
I/O Analysis - статистика операций ввода-вывода
MPI I/O Analysis - статистика MPI I/O
HDF (Hierarchical Data Format) Analysis - анализ использования HDF операций
Analysis GUI - библиотека средств для просмотра SDDF трасс
IO Benchmarks - cбор трасс операций ввода-вывода
URL
http://vibes.cs.uiuc.edu/Software/Pablo/pablo.htm
Где разрабатывается?
Некоммерческий пакет, разработан в университете шт. Иллинойс.
Языки/библиотеки
ANSI C, Fortran 77, Fortran 90 (с ограничениями), HPF (Portland Group).
Платформы
SvPablo - SunOS 5.6, SGI Irix 6.5
Trace Library and Extensions - Sun SunOS, Sun Solaris, RS6000, SP2, Intel Paragon, Convex Exemplar, SGI IRIX
I/O Analysis - Sun Solaris, SGI IRIX
MPI I/O Analysis - Sun SunOS, SGI IRIX
HDF Analysis - Sun Solaris, SGI IRIX
Analysis GUI - Sun Solaris (X11R5+Motif)
IO Benchmarks - Sun Solaris, SGI IRIX, Intel Paragon
Функциональность трассировки.
Уровни детализации. Hа уровне интерфейсов, можно делать ручную разметку с использованием svPablo. Формат трасс - SDDF Тип трасс. Статистика, события.
Визуализация
SvPablo. Основа визуализации - связь с исходным кодом. Представляет цветом число вызовов и общее время фрагмента.
Analysis GUI. Библиотека подпрограмм для визуализации трасс в формате SDDF
Статистика
Развернутые средства статистики, в виде набора пакетов.
I/O Analysis: анализ операций ввода-вывода
MPI I/O Analysis: анализ ввода-вывода MPI функций
HDF Analysis: анализ операций HDF.
Совместимость
Есть конверторы из разных форматов в SDDF – IBM VT Trace, AIMS.
Развитие
Поддержка HPF, Fortran 90. Поддержка MPI 2.0.
Paradyn
URL
http://www.cs.wisc.edu/paradyn
Где разрабатывается?
Некоммерческое средство, разрабатывается в University of Wisconsin,
Версия
4.0
Тип
B (онлайн-анализ)
Языки/библиотеки
Fortran, Fortran 90, C, C++: MPI, PVM; HPF
Платформы
Sun SPARC (только PVM)
Windows NT на x86
IBM RS/6000 (AIX 4.1 или старше)
Функциональность трассировки
Динамическая настраиваемая инструментовка программ во время выполнения. В код программы во время ее выполнения динамической вставляются и убираются вызовы трассирующих процедур. Все делается автоматически, в результате значительно уменьшаются накладные расходы. Начинает с крупных блоков, затем постепенно детализирует узкие места (для этого программа должна достаточно долго работать)
Визуализация
В основе визуализации лежат два вектора
измеряемые параметры производительности: процессорное время, различные накладные расходы, ожидания, времена пересылок и ввода-вывода и т.д.
компоненты программы/вычислительной системы, к которым относятся параметры: процедуры, процессоры, диски, каналы передачи сообщений, барьеры и т.д.
На этих векторах образуется матрица: ее элементы либо скаляр (значение, среднее, минимум, максимум и т.д.), либо временная диаграмма (история изменения характеристики).
Все характеристики отображаются во время исполнения программы.
Проблемы
Есть проблемы с масштабируемостью. На программе при малом числе процессоров (меньше 12) все выглядело нормально, а на большем числе процессоров - более чем 80% увеличение времени. Так же сейчас самой системой занимается очень много памяти.
Развитие
Устранение проблем масштабируемости, уменьшение требуемой памяти, поддержка других платформ.
CXperf
URL
HP Performance Analysis Tools - http://www.hp.com/esy/lang/tools/Performance/ CXperf User's Guide
Где разрабатывается?
Коммерческое средство, разработка Hewlett-Packard.
Тип
A (трассировка + визуализация)
Языки/библиотеки
HP ANSI C (c89), ANSI C++ (aCC), Fortran 90 (f90), HP Parallel 32-bit Fortran 77
Платформы
Сервера HP на базе PA-RISC
Функциональность трассировки
Сбор и настройка трасс осуществляется с помощью указания специальных профилировочных опций компилятора.
Визуализация
3D-визуализация, связь с кодом программы, масштабирование, сопоставительный анализ, графы вызовов.
Некоторые другие средства анализа поведения паралелльных программ:
XMPI - графическая среда запуска и отладки MPI-программ, входит в состав пакета LAM.
HP Pak - набор средств от Hewlett-Packard для анализа поведения многопоточных программ.
TAU (Tuning and Analysis Utilities) - некоммерческий набор утилит анализа производительности программ, написанных на языке C++ и его параллельных вариантах. Включает пакет профилировки TAU Portable Profiling.
Chiron - средство для оценки производительности многопроцессорных систем с общей памятью.
GUARD - параллельный отладчик.
MPP-Apprentice - средство в составе Message-Passing Toolkit от SGI.
XPVM - графическое средство мониторинга PVM-программ.
Подробнее можно прочитать в [8].
4. Характеристики и методика отладки DVM-программ
4.1 Основные характеристики производительности
Возможность различать последовательные и параллельные участки программы позволяет при ее выполнении на многопроцессорной ЭВМ спрогнозировать время, которое потребуется для выполнения этой программы на однопроцессорной ЭВМ. Это время называется полезным временем. Тем самым появляется возможность вычислить главную характеристику эффективности параллельного выполнения - коэффициент эффективности, равный отношению полезного времени к общему времени использования процессоров, которое в свою очередь равно произведению времени выполнения программы на многопроцессорной ЭВМ (максимальное значение среди времен выполнения программы на всех используемых ею процессорах) на число используемых процессоров. Разница между общим временем использования процессоров и полезным временем представляет собой потерянное время. Если программист не удовлетворен коэффициентом эффективности выполнения своей программы, то он должен проанализировать составляющие части потерянного времени и причины их возникновения.
Существуют следующие составляющие потерянного времени:
потери из-за недостатка параллелизма, приводящего к дублированию вычислений на нескольких процессорах (недостаточный параллелизм). Дублирование вычислений осуществляется в двух случаях. Во-первых, последовательные участки программы выполняются всеми процессорами. Во-вторых, витки некоторых параллельных циклов могут быть по указанию программиста полностью или частично размножены.
потери из-за выполнения межпроцессорных обменов (коммуникации).
потери из-за простоев тех процессоров, на которых выполнение программы завершилось раньше, чем на остальных (простои).
Время выполнения межпроцессорных обменов, помимо времени пересылки данных с одного процессора на другой, может включать в себя и время, которое тратится из-за того, что операция приема сообщения на одном процессоре выдана раньше соответствующей операции посылки сообщения на другом процессоре. Такая ситуация называется рассинхронизацией процессоров и может быть вызвана разными причинами.
Поскольку потери, вызываемые рассинхронизацией процессоров, очень часто составляют подавляющую часть времени коммуникаций, то важно предоставить программисту информацию, позволяющую ему оценить эти потери и найти их причины. Однако, точное определение потерь, вызванных рассинхронизацией, связано со значительными накладными расходами
Если какая-либо из перечисленных операций выдана разными процессорами не одновременно, то при ее выполнении возникнут потери из-за рассинхронизации процессоров. Для оценки величины таких потерь для каждой коллективной операции вычисляются потенциальные потери из-за ее неодновременного запуска - время, которое было бы потрачено всеми процессорами на синхронизацию, если бы выполнение любой коллективной операции начиналось бы с синхронизации процессоров. При этом накладные расходы на пересылку синхронизационных сообщений игнорируются.
Для оценки суммарных потенциальных потерь, которые могут возникнуть из-за неодновременного запуска коллективных операций на разных процессорах, служит специальная характеристика – синхронизация.
Основная причина потерь из-за рассинхронизации, на устранение которой должен быть нацелен программист – разбалансировка загрузки процессоров. Разбалансировка может возникать из-за того, что выполняющиеся в параллельном цикле вычисления распределены между процессорами неравномерно.
Если бы при входе в каждый параллельный цикл и при выходе из него производилась бы синхронизация процессоров (межпроцессорный обмен), то разбалансировка загрузки процессоров обязательно приводила бы к потерям из-за рассинхронизации. Однако, поскольку такая синхронизация осуществляется не для всех циклов, то разбалансировка на разных участках программы может компенсироваться и реальные потери могут быть незначительными или вообще отсутствовать. Для оценки возможных потерь из-за разбалансировки программисту может выдаваться некоторая обобщенная характеристика - разбалансировка. С целью снижения накладных расходов при вычислении этой характеристики делается предположение, что синхронизация процессоров будет производиться только один раз - при завершении выполнении программы. Поэтому сначала для каждого процессора определяется его суммарная вычислительная загрузка, а затем прогнозируется вызываемая разбалансировкой величина потерь из-за рассинхронизации. Однако, поскольку в реальной программе синхронизация процессоров осуществляется не только при завершении программы, а гораздо чаще, то реальные потери будут превосходить эту величину. Реальные потери из-за рассинхронизации будут еще более превосходить величину разбалансировки в том случае, когда вычислительная загрузка процессоров сильно изменяется при многократном выполнении одного и того же параллельного цикла.
Рассинхронизация может возникать не только из-за разбалансировки, но также из-за различий во временах завершения выполнения на разных процессорах одной и той же коллективной операции, вызванных особенностями ее реализации на конкретной параллельной ЭВМ. Для оценки величины такой потенциальной рассинхронизации программисту может выдаваться специальная характеристика – разброс времен завершения коллективных операций. Как и время разбалансировки, эта характеристика является интегральной. Она достаточно точно отражает возможные потери из-за рассинхронизации в том случае, когда различия времен выполнения коллективных операций не являются случайными, а определяются, например, топологией коммуникационной сети или функциональной специализацией процессоров (процессор ввода-вывода, процессор-исполнитель редукционных операций, и т.п.).
Важной характеристикой, отражающей степень совмещения межпроцессорных обменов с вычислениями, является время перекрытия обменов вычислениями.
Основные характеристики эффективности являются интегральными характеристиками, позволяющими оценить степень распараллеливания программы и основные резервы ее повышения. Однако для исследования эффективности сложных программ одних интегральных характеристик может оказаться недостаточно. В таком случае программист хочет получить более подробную информацию о выполнении своей программы и ее отдельных частей.
4.2 Методика отладки эффективности
Для анализа эффективности выполнения сложных параллельных программ недостаточно иметь характеристики выполнения всей программы целиком, а требуется уметь детализировать эти характеристики применительно к отдельным частям программы.
В системе DVM были реализованы соответствующие средства, которые позволяют представить выполнение программы в виде иерархии интервалов [подробнее - 6].
Интервалы:
Выполнение всей программы целиком рассматривается как интервал самого высокого (нулевого) уровня. Этот интервал может включать в себя несколько интервалов следующего (первого) уровня. Такими интервалами могут быть параллельные циклы, последовательные циклы, а также любые отмеченные программистом последовательности операторов, выполнение которых всегда начинается с выполнения первого оператора, а заканчивается выполнением последнего. Все описанные выше характеристики вычисляются не только для всей программы, но и для каждого ее интервала. При этом многократное выполнение интервала может рассматриваться (с некоторой долей условности) как выполнение на тех же процессорах отдельной программы, состоящей из развернутой последовательности тех операторов интервала, которые были выполнены при реальном прохождении параллельной программы. Фактически же, характеристики таких многократно выполняемых интервалов накапливаются при каждом их выполнении. При этом интервалы, входящие в состав одного и того же интервала более высокого уровня, идентифицируются именем файла с исходным текстом программы и номером строки в нем, соответствующим началу интервала, а также, возможно, некоторым приписанным ему программистом целочисленным номером.
Разбиением программы на интервалы пользователь управляет при ее компиляции. Он может задать такие режимы, при которых интервалами будут последовательные циклы, которые содержат внутри себя параллельные циклы, либо все последовательные циклы вообще, либо отмеченные им в программе последовательности операторов.
4.3 Рекомендации по анализу
При разработке параллельной программы пользователь, как правило, преследует одну из двух возможных целей – обеспечить решение задачи в приемлемые сроки, либо создать программу, способную эффективно решать на различных параллельных ЭВМ задачи определенного класса.
В первом случае, если время выполнения программы удовлетворяет пользователя, то другие характеристики его могут уже не интересовать. Во втором случае главным критерием для пользователя является коэффициент эффективности распараллеливания. Если время выполнения или коэффициент эффективности не удовлетворяет пользователя, то ему необходимо анализировать потерянное время и его компоненты.
Важно помнить, что: во-первых, потерянное время (как и коэффициент эффективности распараллеливания) вычисляется, опираясь не на реальное время выполнения программы на одном процессоре, а на прогнозируемое время. Этот прогноз может отличаться от реального времени и в ту, и в другую сторону.
Реальное время может быть больше прогнозируемого из-за того, что при выполнении программы на одном процессоре одни и те же вычисления могут осуществляться медленнее, чем при выполнении на нескольких процессорах. Это объясняется тем, что при изменении объема используемых при вычислениях данных меняется скорость доступа к ним через кэш-память. Поскольку производительность современных процессоров сильно зависит от эффективности использования кэш-памяти, то реальное время может заметно превысить прогнозируемое.
Реальное время может быть меньше прогнозируемого, поскольку при прогнозе учитываются не все накладные расходы на поддержку выполнения параллельной программы. Эти неучтенные расходы, например, поиск информации в системных таблицах при выполнении некоторых часто используемых функций (замерять время выполнения которых невозможно без внесения неприемлемых искажений в выполнение программы), могут значительно сократиться при уменьшении количества процессоров до одного.
В результате влияния эффективности использования кэш-памяти и системных накладных расходов при выполнении программы на разных конфигурациях параллельной ЭВМ будут выдаваться различные значения полезного времени. Поэтому, если есть возможность выполнить программу на одном процессоре (а она может требовать гораздо больше оперативной памяти, чем имеется на одном процессоре), то желательно это сделать для получения представления об отличиях прогнозируемых времен от реального времени.
Во-вторых, время выполнения параллельной DVM-программы на одном процессоре может значительно отличаться от времени ее выполнения как последовательной программы. Это может быть следствием следующих причин:
Доступ к распределенным данным в параллельной программе отличается от доступа к ним в последовательной программе. Дополнительные накладные расходы, появляющиеся в параллельной программе, могут увеличить время ее выполнения на 10-30 процентов. Однако в параллельной программе может быть проведена такая оптимизация доступа к данным, которая для некоторых программ приведет к ускорению их выполнения по сравнению с последовательным случаем.
Трансформация программы в программу на стандартных языках Фортран 77 или Си может привести к различиям в оптимизации программ стандартными компиляторами. В результате, параллельная программа может выполняться либо медленнее, либо быстрее. Особенности оптимизации программ современными компиляторами существенно (десятки и сотни процентов) определяют эффективность их выполнения.
Некоторые накладные расходы на поддержку выполнения параллельной программы могут значительно замедлить ее выполнение (например, операции запроса и освобождения памяти в последовательной программе могут превратиться в параллельной программе в гораздо более сложные операции создания и уничтожения распределенного массива).
Поэтому, если есть возможность выполнить программу как обычную последовательную программу на одном процессоре (если это нельзя сделать на параллельной ЭВМ, то может быть это окажется возможным на рабочей станции), то желательно это сделать.
Все это пользователю необходимо иметь в виду, приступая к анализу потерянного времени и его компонент.
Сначала следует оценить три компоненты потерянного времени для интервала нулевого уровня (всей программы). Наиболее вероятно, что основная доля потерянного времени приходится на одну из первых двух компонент (недостаточный параллелизм или коммуникации).
В случае если причиной оказался недостаточный параллелизм, необходимо уточнить, на каких участках он обнаружен – последовательных или параллельных. В последнем случае причина может быть очень простой – неверное задание матрицы процессоров при запуске программы или неверное распределение данных и вычислений. Если же недостаточный параллелизм обнаружен на последовательных участках, то причиной этого, скорее всего, является наличие последовательного цикла, выполняющего большой объем вычислений. Устранение этой причины может потребовать больших усилий.
В том же случае, если основной причиной потерь являются коммуникации, то необходимо, прежде всего, обратить внимание на характеристику потери из-за рассинхронизации. Если ее значение близко к размерам потерь из-за коммуникаций, то необходимо рассмотреть характеристику разбалансировка, поскольку именно разбалансировка вычислений в параллельном цикле является наиболее вероятной причиной рассинхронизации и больших потерь на коммуникациях. Если величина разбалансировки намного меньше величины синхронизации, то необходимо обратить внимание на величину разброса времен коллективных операций. Если рассинхронизация не является следствием разброса времен завершения коллективных операций, то ее возможной причиной могут быть разбалансировки некоторых параллельных циклов, которые на рассматриваемом интервале выполнения программы могли взаимно компенсироваться. Поэтому имеет смысл перейти к рассмотрению характеристик разбалансировки на интервалах более низкого уровня.
Второй вероятной причиной больших потерь из-за рассинхронизации может быть рассинхронизация процессоров, которая возникает при выдаче операций ввода-вывода. Это происходит из-за того, что основная работа (обращение к функциям ввода-вывода операционной системы) производится на процессоре ввода-вывода, а остальные процессоры в это время ждут получения от него данных или информации о завершении коллективной операции. Эту причину потерь легко обнаружить, обратив внимание на соответствующую компоненту характеристики коммуникации – потери из-за коммуникаций при вводе-выводе.
Еще одной причиной больших потерь из-за коммуникаций могут оказаться задержки при запуске коллективных операций в асинхронном режиме, возникающие из-за того, что некоторые реализации MPI не обеспечивают совмещение вычислений с обменами.
Возможен и другой подход к анализу характеристик, когда сначала анализируются коэффициенты эффективности и потерянное время на различных интервалах первого уровня, затем второго уровня, и т.д. В результате определяется критический участок программы, на анализ характеристик которого и направляются основные усилия. При этом необходимо иметь в виду, что причиной потерь на данном интервале из-за рассинхронизации и простоев могут быть разбалансировки и разбросы времен не только на этом интервале, но и на других, выполнявшихся до него интервалах.
При отладке производительности программы пользователь не обязательно должен запускать ее с тем большим объемом вычислений, который будет характерен для использования программы при решении реальных задач. Он может ограничить, например, количество регулярно повторяющихся внешних итераций до одной - двух итераций. При этом коэффициент эффективности программы, существенно зависящий от потерь на тех участках программы, которые выполняются до начала первой итерации или после окончания последней итерации, может значительно снизиться. Однако пользователь может оформить выполнение внешних итераций в виде отдельного интервала (но при этом надо учитывать тот факт, что выполнение первой итерации может сопровождаться значительными задержками из-за динамической подзагрузки программы из файловой системы) и отлаживать его производительность по той же методике, которая была описана выше применительно к программе целиком.
5. Средство анализа эффективности MPI программ
5.1 Постановка задачи
В системе DVM существуют развитые средства анализа эффективности выполнения параллельной DVM-программы. Эти средства являются более мощными, чем те, которые существуют для MPI-программ, поскольку многие важные характеристики выполнения MPI-программ (например, соотношение параллельных и последовательных вычислений) невозможно определить из-за отсутствия необходимой информации. Кроме того, в настоящее время при разработке MPI-программ у нас в стране практически не используются инструментальные средства отладки эффективности. Это вызвано следующими основными факторами: - разные средства требуют от пользователя знания их собственного интерфейса (отсутствие фактического стандарта); - отсутствием вообще каких-либо инструментальных средств анализа эффективности на многих параллельных ЭВМ.
Поэтому важно создать такие средства для получения характеристик эффективности MPI-программ, которые могли бы быть доступны пользователям на любых многопроцессорных ЭВМ.
Целью данной дипломной работы является создание экспериментальной системы отладки эффективности MPI-программ.
Входными данными для нее будут трассы, создаваемые DVM-системой для функциональной отладки MPI-программ. В этих трассах отражены обращения к MPI-функциям и времена их работы. Для получения характеристик, аналогичных тем, которые выдаются для DVM-программ, от программиста потребуется дополнительная информация о том, какие вычисления являются параллельными, а какие последовательными (дублированными на каждом процессоре). Эти указания должны быть оформлены таким образом, что их наличие в MPI-программе не мешало ее правильному и эффективному выполнению на тех ЭВМ, где отсутствует данная система отладки эффективности MPI-программ. Таким же образом должны оформляться и средства описания тех интервалов выполнения программы, для которых требуется отдельно собирать все характеристики эффективности.
Этапы работы анализатора.
В работе анализатора можно выделить следующие этапы.
Этап 1
Обработка трасс со всех процессоров и вычисление для каждого интервала и каждого процессора следующих характеристик:
Основные характеристики и их компоненты
Коэффициент эффективности (Parallelization efficiency) равен отношению полезного времени к общему времени использования процессоров.
Время выполнения (Execution time).
Число используемых процессоров (Processors).
Общее время использования процессоров (Total time) - произведение времени выполнения (Execution time) на число используемых процессоров (Processors).
Полезное время (Productive time) – прогнозируемое время выполнения на одном процессоре
Потерянное время (Lost time).
Коммуникации (Communication) и все компоненты.
Простои (Idle time).
Разбалансировка (Load_Imbalance).
Потенциальные потери из-за синхронизации (Synchronization) и все компоненты.
Потенциальные потери из-за разброса времен (Time_variation) и все компоненты.
Характеристики выполнения программы на каждом процессоре
Потерянное время (Lost time) - сумма его составляющих – потерь из-за недостаточного параллелизма (User insufficient_par), системных потерь из-за недостаточного параллелизма (Sys insufficient_par), коммуникаций (Communication) и простоев (Idle time).
Простои на данном процессоре (Idle time) - разность между максимальным временем выполнения интервала (на каком-то процессоре) и временем его выполнения на данном процессоре.
Общее время коммуникаций (Communication).
Реальные потери из-за рассинхронизации (Real synchronization).
Потенциальные потери из-за разброса времен (Variation).
Разбалансировка (Load_imbalance) вычисляется как разность между максимальным процессорным временем (CPU+MPI) и соответствующим временем на данном процессоре.
Время выполнения интервала (Execution_time).
Полезное процессорное время (User CPU_time).
Полезное системное время (MPI time).
Число используемых процессоров для данного интервала (Processors).
Времена коммуникаций для всех типов коллективных операций
Реальные потери из-за рассинхронизации для всех типов коллективных операций.
Потенциальные потери из-за рассинхронизации для всех типов коллективных операций.
Потенциальные потери из-за разброса времен для всех типов коллективных операций.
Этап 2
Подготовка текстового представления вычисленных характеристик. Такое представление упрощает первоначальный анализ характеристик при запуске параллельной программы на удаленной ЭВМ.
Этап 3
Визуализация результатов анализа эффективности.
Подсистема визуализации должна обеспечить графическое представление вычисленных характеристик эффективности и помочь пользователю их исследовать - позволить с разной степенью подробности просматривать историю выполнения программы и объяснять, как были вычислены те или иные характеристики.
5.3 Устройство анализатора
Итак, анализатор состоит из трех основных компонент.
Первая – сбор информации по трассе. Вторая – анализ собранных данных. Третья – визуализация.
5.3.1 Сбор трассы
При каждом запуске параллельной программы в режиме трассировки, создается группа файлов с информацией обо всех ключевых событиях в трассе. Тут есть времена и параметры всех событий, которые имели место при выполнении программы. К этим данным есть возможность доступа через специальные функции интерфейса. Также можно получить информацию для разного рода вспомогательных таблиц (имена используемых функций, исходных файлов и т.п.).
Далее полученные данные поступают на вход модулям анализа и сбора характеристик.
5.3.2 Анализ
В соответствии с описанной в пункте 4.2 методикой, вся программа будет разбита на систему интервалов, точнее дерево интервалов. Корнем дерева будет вся программа, она считается интервалом нулевого уровня.
Далее в соответствии с вложенностью интервалы первого уровня и т.д.
Как указать границы интервалов?
Для этого используются пара функций MPI_Send() и MPI_Recv() для указания начала интервала, и такая же пара для указания его окончания. При этом посылка и прием сообщения происходят самому себе и от самого себя (имеется ввиду, что в качестве номера отправителя/получателя используется номер самого процесса). Кроме того, тэг сообщения имеет следующий вид:
TAG = 0x(aa)(id)(aa/bb).
Тэг является четырехбайтным целым числом. Первый байт у «нашего» тэга – это 0xaa. Это позволяет отличить его от обычных посылок/приемов сообщений. Последний байт может быть 0xaa – символизирует начало интервала, 0xbb – конец интервала. Внутри специальный идентификатор интервала (2 байта), его можно использовать, например, для того, чтобы отдельно выделить итерации цикла.
Такой способ выделения был выбран потому, что:
он всегда попадает в трассировку (некоторые специальные функции вроде MPI_Pcontrol() в текущей версии трассировщика не попадают).
занимает относительно немного времени (порядка 100 тиков процессора).
прост в использовании и не требует дополнительных средств, помимо стандартных MPI-функций.
Таким образом, программист может добавить в свой код границы интересующих его областей программы (в нашей терминологии интервалы).
Далее по этим тэгам среди всех событий будут найдены те, которые являются границами интервалов и будут определены их идентификаторы.
Для этого вводится специальный класс:
class ;line-height: 150%; widows: 0; orphans: 0"> {
public:
;line-height: 150%; widows: 0; orphans: 0"> friend bool operator <( const ;line-height: 150%; widows: 0; orphans: 0"> bool enter_leave;
unsigned long time;
int identity;
unsigned int proc;
unsigned int scl;
};
И функция:
vector<;line-height: 150%; widows: 0; orphans: 0"> которая и вычисляет=> определяет необходимые границы вместе со всеми параметрами.
После определения границ, создается структура дерево, в которой хранятся все данные обо всех интервалах.
Кратко об используемых структурах данных.
Создан специальный класс tree:
class tree
{
public:
static int Intervallevel; // current interval level
static int IntervalID; // current interval ID
long index;
int level; // Interval level
int EXE_count;
int source_line;
string source_file;
int ID;
//Characteristics for every interval
unsigned long Exec_time;
unsigned long Productive_time;
double Efficiency;
unsigned long CPU_time;
unsigned long MPI_time;
unsigned long Lost_time;
unsigned long Comm_time;
unsigned long SendRecv_time;
unsigned long CollectiveAll_time;
unsigned long Idle_time;
unsigned long AllToAll_time;
unsigned long Time_variation;
unsigned long Potent_sync;
unsigned long T_start;
vector < pair
//for intelval's tree
tree* parent_interval;
int count;
vector
vector
};
Этот класс содержит информацию обо всех характеристиках данного интервала, описанных в 5.2. Кроме того, в нем есть информация о родительском узле дерева, а также обо всех «листьях-потомках».
В этом классе в качестве вспомогательного используется класс Processors.
class Processors
{
public:
unsigned long enter_time;
unsigned long leave_time;
unsigned int number;
unsigned long MPI_time;
unsigned long SendRecv_time;
unsigned long CollectiveAll_time;
unsigned long Idle_time;
unsigned long AllToAll_time;
unsigned long CPU_time;
unsigned long Comm_time;
unsigned long Time_variation;
unsigned long Potent_sync;
unsigned long T_start;
};
В этом классе содержатся элементарные составляющие всех компонентов, собранные на каждом интервале каждого процессора.
Далее, после определения границ интервалов, происходит создание дерева интервалов. В этом дереве и будет храниться информация обо всех интервалах.
Класс tree включает методы, которые и собирают информацию из структур, собранных на трассе.
Первая группа характеристик собирается в функции
Leave(int line, char* file, long index,unsigned int proc,unsigned long time).
MPI_time Используем – getMPITimebyProc();
SendRecv_time - getSendRecvCommunicationTimebyProc();
CollectiveAll_time – getCollectiveAllByProc();
AllToAll_time - getAllToAllByProc();
Potent_sync - getPotentSyncByProc();
Time_variation - getTimeVariationByProc();
T_start - getNonBlockedTimebyProc();
Вычисление характеристик.
getMPITimebyProc() – Происходит суммирование интервалов времени, занятых под MPI-функции (интервалы получаются как разность между временем выхода и входа в MPI-функцию).
getSendRecvCommunicationTimebyProc( )- Происходит суммирование интервалов времени, вычисляемых как разность времени выхода из функции приема сообщения и времени входа в функцию посылки сообщения.
getPotentSyncByProc() – Вычисляется по-разному для операций одиночных посылок/приемов сообщений и коллективных операций. Сюда входят все случаи, когда Recv был выдан раньше Send’а. Эти «задержки» как раз и суммируются. Для коллективных же операций суммируется время «задержки» старта операции на некоторых процессорах.
getTimeVariationByProc() – Вычисляется время, рассинхронизации окончания коллективной операции.
getNonBlockedTimebyProc() – Вычисляется аналогично getMPITimebyProc(), только суммируются времена работы только не блокирующих операций.
Все эти характеристики собираются на каждом процессоре для данного интервала. Прототип всех функций одинаков:
getFunction(unsigned long enter_time, unsigned long leave_time, unsigned int proc).
Собранные «элементарные» характеристики, затем собираются в более общие по всему интервалу.
Первая используемая для этого функция – это функция Integrate().
В этой функции собираются следующие характеристики:
CPU_time
MPI_time
SendRecv_time
CollectiveAll_time
AllToAll_time
Comm_time(Общее время коммуникаций)
Idle_time(время бездействия)
Potent_sync
Time_variation
T_start
Все они уже являются характеристиками всего интервала.
Далее происходит вычисление уже не общих, а сравнительных характеристик. Зная все эти компоненты на каждом процессоре для интервала, мы находим процессоры с максимальным, минимальным значением по времени, а также среднее значения всех характеристик.
После функции Integrate() вычисляется полезное время calculateProductive(), потом время запуска - calculateExecution(),
эффективность распараллеливания - efficiency(), и, наконец, потерянное время – calculateLost().
На этом сбор и анализ информации оканчиваются. Следующий этап, это генерация соответствующих текстовых выдач. Эти выдачи представляют собой текстовый файл и имеют следующий вид (Пример).
Пример. Текстовый файл с итоговыми характеристиками.
Interval (LineNumber = 153 SourceFile = exch.c) Level=0 EXE_Count=1
---Main Characteristics---
Parallelization Efficiency 0.978833
Execution Time 2.079975
Processors 4
Total Time 8.319900
Productive Time 8.143794 (CPU MPI)
MPI время на одном процессоре считается полезным, а на остальных - потерянным
Lost Time 0.176106
---MPI Time 0.173490
---Idle Time 0.002616
Communication Time 0.076563
*****SendRecv Time 0.013295
*****CollectiveAll Time 0.063268
*****AllToAll Time 0.000000
Potential Sync. 0.068763
Time Variation 0.001790
Time of Start 0.000000
---Comparative Characteristics---
Tmin Nproc Tmax Nproc Tmid
Lost Time 0.033087 3 0.060057 0 0.044026
Idle Time 0.000000 1 0.000898 0 0.000654
Comm. Time 0.006597 3 0.034854 0 0.019140
MPI Time 0.032259 3 0.059159 0 0.043372
Potential Sync. 0.001800 0 0.029369 3 0.017190
Time variation 0.000161 1 0.000607 3 0.000447
Time of Start 0.000000 0 0.000000 0 0.000000
Для каждого интервала выдается следующая информация:
имя файла с исходным текстом MPI-программы и номер первого оператора интервала в нем (SourceFile, LineNumber);
номер уровня вложенности (Level);
количество входов (и выходов) в интервал (EXE_Count);
основные характеристики выполнения и их компоненты (Main characteristics);
минимальные, максимальные и средние значения характеристик выполнения программы на каждом процессоре (Comparative characteristics);
При выдаче характеристик их компоненты располагаются в той же строке (справа в скобках), либо в следующей строке (справа от символов “*” или “-“).
Информация о минимальных, максимальных и средних значениях характеристик оформлена в таблицу. Также есть информация обо всех характеристиках на каждом процессоре.
Следующим этапом после того, как все необходимые характеристики собраны, является этап визуализации.
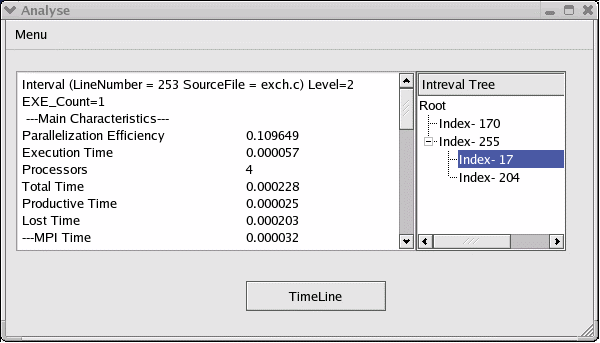
Этот этап необходим, так как хотя текстовый файл содержит всю необходимую информацию, при большом числе интервалов пользоваться им не очень удобно. Кажется целесообразным, что, так как интервалы “отображались” логически в виде дерева, то и визуализировать их нужно в виде дерева. Было выбрана форма отображения, аналогичная древовидной организации файловой структуры данных на дисках. Соответственно, каждый интервал доступен из своего родителя, интервалы нижних уровней отображаются правее. Также при нажатии на интервал, в текстовое поле
выводится информация обо всех характеристиках именно этого интервала.
Это значительно облегчает поиск необходимой для анализа области.
Рис.6. Окно программы анализа.
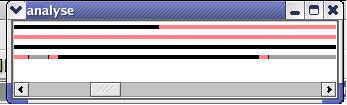
Также полезным для представления общей картины запуска является упорядоченный по времени список событий. При этом используется так называемый (TimeLine), все события отображаются на линии определенным цветом в соответствии со временем, когда они произошли. Это позволяет отслеживать не просто нужную область, а точно интересующее событие.
Используя механизм Tooltip’ов, пользователь получает возможность узнать тип события (пользовательский (UserCode) или MPI) и название функции (для MPI - функций).
Рис.7. TimeLine
Узнать это можно по цвету линии с событием. Список цветов описан в Приложении 2.
Заключение
В данной работе исследовались возможности анализа эффективности MPI-программ. Было разработано собственное программное средство, использующее подходы, применяемые в DVM-системе.
Приблизительный объем программы на С++ в строках кода = 6500 строк.
Программа оттестирована на тестах, поставляемых с MPI – реализациями, а также с тестами NAS (NPB2.3), с добавлением описанных выше директив для границ интервала.
В процессе дипломной работы были:
Проанализированы современные средства анализа параллельных программ.
Изучены алгоритмы анализа и сбора характеристик.
Реализовано программное средство со следующими возможностями:
Отображение выполнения программы в виде дерева интервалов
Сбор и отображение характеристик выбранного интервала.
Выдача общей информации обо всех интервалах в текстовый файл.
Показ time-line.
Выводы:
Отладка эффективности параллельных программ – процесс очень сложный и трудоемкий
Развитые средства анализа эффективности могут существенно ускорить этот процесс.
Необходима грамотная - наглядная визуализация результатов.
Для достижения эффективности параллельной программы приходится многократно изменять программу, иногда кардинально меняя схему ее распараллеливания. Поэтому важно использовать высокоуровневые средства разработки параллельных программ
Необходимо учитывать различные эффекты, связанные с нестабильностью поведения параллельных программ.
В дальнейшем планируется вести работу в направлении интеллектуализации системы. Желательно получение автоматических советов пользователю-программисту по улучшению эффективности программы. Это поможет упростить решение традиционных сложностей, возникающих на пути отладки параллельной программы.
Структура программы.
main
determine
compute
tree
visual
timeline
characteristics
Модуль main – вызов процедур сбора информации, анализа и генерации результата. Compute – вычисление все необходимых характеристик трассы. Для этого используется модуль tree, который отвечает за формирование дерева с данными об искомых характеристиках. Модуль determine позволяет находить и выделять интервалы в исходном коде и в трассе программы. Модуль visual занимается графическим отображением полученных данных и состоит и timeline – события в трассе, и characteristics – дерево интервалов с отображаемыми характеристиками.
Приложение 2
Используемые цвета на TimeLine:
1. Коллективные операции:
MPI_Barrier, MPI_Bcast, MPI_Gather, MPI_Gatherv, MPI_Scatter, MPI_Scatterv, MPI_Allgather, MPI_Allgatherv, MPI_Alltoall, MPI_Alltoallv, MPI_Reduce, MPI_Allreduce, MPI_Reduce_scatter, MPI_Scan
черный
2. Операции посылки
MPI_Send, MPI_Bsend, MPI_Ssend, MPI_Rsend
тёмно-зелёный
3. Неблокирующие операции посылки
MPI_Isend, MPI_Ibsend, MPI_Issend, MPI_Irsend
светло-зелёный
4. Операции получения/ожидания/посылки-получения с блокировкой MPI_Recv, MPI_Wait, MPI_Waitany, MPI_Waitall, MPI_Waitsome, MPI_Probe, MPI_Sendrecv, MPI_Sendrecv_replace
темно-синий
5. Операции получения/проверки без блокировки
MPI_Irecv, MPI_Test, MPI_Testany, MPI_Testall, MPI_Testsome, MPI_Iprobe голубой
6. Другие (малоиспользуемые) операции
MPI_Request_free, MPI_Cancel, MPI_Test_cancelled, MPI_Send_init, MPI_Bsend_init, MPI_Ssend_init, MPI_Rsend_init, MPI_Recv_init, MPI_Start, MPI_Startall
светло-серый
7. Пользовательский код
светло-розовый

Нравится материал? Поддержи автора!
Ещё документы из категории информатика:
Чтобы скачать документ, порекомендуйте, пожалуйста, его своим друзьям в любой соц. сети.
После чего кнопка «СКАЧАТЬ» станет доступной!
Кнопочки находятся чуть ниже. Спасибо!
Кнопки:
Скачать документ