Использование нейросетей для построения системы распознавания речи
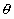
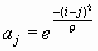
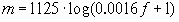
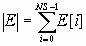
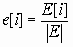
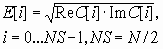
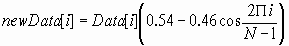
 Содержание
Содержание
Введение
1. Распознавание речи – ключевые моменты
2. Возможность использования нейросетей для построения системы распознавания речи
3. Самообучающиеся автономные системы
4. Система распознавания речи как самообучающаяся система
5. Описание системы
5.1 Ввод звука
5.2 Наложение первичных признаков на вход нейросети
5.3 Модель нейросети
5.4 Обучение нейросети
6. Применение
Список использованных источников
Введение
Я думаю, нет смысла рассказывать о том, зачем нужно исследование искусственных нейронных сетей, чем они привлекают исследователей и какие новые возможности они открывают перед разработчиками систем обработки информации - если Вы сейчас читаете эту статью, то Вам итак все ясно. Если же Вы новичок в области нейрокомпьютинга и всего, что с ним связано, то существует огромное количество статей, научных публикаций, учебной литературы, посвященной нейросетям ([1],[5],[6],[8]); написано множество программ, создано множество работающих образцов (от простых исследовательских моделей до полнофункциональных промышленных систем), в которых используются нейросети. В общем, теоретическое исследование нейросетевых алгоритмов ведется уже давно, и на данный момент они уже широко применяются для решения практических задач. В связи с очевидной конкурентоспособностью этого способа обработки информации по сравнению с существующими на сегодняшний момент традиционными способами особый интерес представляет проблема определения круга задач, для которых было бы эффективным применение нейросетевых алгоритмов. Распознавание образов – это одна из задач, успешно решаемых нейросетями. Одним из приложений теории распознавания образов является распознавание речи. Проблема распознавания речи как одно из составляющих искусственного интеллекта давно привлекала исследователей, и на сегодняшний день хоть и достигнуты определенные успехи, она остается открытой. Объединенная с проблемой синтеза речи, она представляет очень интересное поле для исследований.
Попытаться применить нейросетевые алгоритмы на практике, описать и решить возникшие проблемы, а также разработать теорию автономных самообучающихся систем и реализовать её на конкретном примере – вот какие задачи ставились в рамках этой работы.
1. Распознавание речи – ключевые моменты
Что понимается под распознаванием речи? Это может быть преобразование речи в текст, распознавание и выполнение определенных команд, выделение из речи каких либо характеристик (например, идентификация диктора, определение его эмоционального состояния, пола, возраста, и т.д.) – все это в разных источниках может попасть под это определение. В моей работе под распознаванием речи понимается отнесение звуков речи или их последовательности (фонем, букв, слов) к какому-либо классу. Затем этому классу могут быть сопоставлены символы алфавита – получим систему преобразования речи в текст, или определенные действия – получим систему выполнения речевых команд. Вообще этот способ обработки речевой информации может использоваться на первом уровне какой-либо системы с гораздо более сложной структурой. И от эффективности этого классификатора будет зависеть эффективность работы системы в целом.
Какие проблемы возникают при построения системы распознавания речи? Главная особенность речевого сигнала в том, что он очень сильно варьируется по многим параметрам: длительность, темп, высота голоса, искажения, вносимые большой изменчивостью голосового тракта человека, различными эмоциональными состояниями диктора, сильным различием голосов разных людей. Два временных представление звука речи даже для одного и того же человека, записанные в один и тот же момент времени, не будут совпадать. Необходимо искать такие параметры речевого сигнала, которые полностью описывали бы его (т.е. позволяли бы отличить один звук речи от другого), но были бы в какой-то мере инвариантны относительно описанных выше вариаций речи. Полученные таким образом параметры должны затем сравниваться с образцами, причем это должно быть не простое сравнение на совпадение, а поиск наибольшего соответствия. Это вынуждает искать нужную форму расстояния в найденном параметрическом пространстве.
Далее, объем информации, которую может хранить система, не безграничен. Каким образом запомнить практически бесконечное число вариаций речевых сигналов? Очевидно, здесь не обойтись без какой-либо формы статистического усреднения.
Ещё одна проблема – это скорость поиска в базе данных. Чем больше её размер, тем медленнее будет производиться поиск – это утверждение верно, но только для обычных последовательных вычислительных машин. А какие же ещё машины смогут решить все вышеперечисленные проблемы? – спросите Вы. Совершенно верно, это нейросети.
2. Возможность использования нейросетей для построения системы распознавания речи
Классификация - это одна из «любимых» для нейросетей задач. Причем нейросеть может выполнять классификацию даже при обучении без учителя (правда, при этом образующиеся классы не имеют смысла, но ничто не мешает в дальнейшем ассоциировать их с другими классами, представляющими другой тип информации – фактически наделить их смыслом). Любой речевой сигнал можно представить как вектор в каком-либо параметрическом пространстве, затем этот вектор может быть запомнен в нейросети. Одна из моделей нейросети, обучающаяся без учителя – это самоорганизующаяся карта признаков Кохонена. В ней для множества входных сигналов формируется нейронные ансамбли, представляющие эти сигналы. Этот алгоритм обладает способностью к статистическому усреднению, т.е. решается проблема с вариативностью речи. Как и многие другие нейросетевые алгоритмы, он осуществляет параллельную обработку информации, т.е. одновременно работают все нейроны. Тем самым решается проблема со скоростью распознавания – обычно время работы нейросети составляет несколько итераций.
Далее, на основе нейросетей легко строятся иерархические многоуровневые структуры, при этом сохраняется их прозрачность (возможность их раздельного анализа). Так как фактически речь является составной, т.е. разбивается на фразы, слова, буквы, звуки, то и систему распознавания речи логично строить иерархическую.
Наконец, ещё одним важным свойством нейросетей (а на мой взгляд, это самое перспективное их свойство) является гибкость архитектуры. Под этим может быть не совсем точным термином я имею в виду то, что фактически алгоритм работы нейросети определяется её архитектурой. Автоматическое создание алгоритмов – это мечта уже нескольких десятилетий. Но создание алгоритмов на языках программирования пока под силу только человеку. Конечно, созданы специальные языки, позволяющие выполнять автоматическую генерацию алгоритмов, но и они не намного упрощают эту задачу. А в нейросетях генерация нового алгоритма достигается простым изменением её архитектуры. При этом возможно получить совершенно новое решение задачи. Введя корректное правило отбора, определяющее, лучше или хуже новая нейросеть решает задачу, и правила модификации нейросети, можно в конце концов получить нейросеть, которая решит задачу верно. Все нейросетевые модели, объединенные такой парадигмой, образуют множество генетических алгоритмов. При этом очень четко прослеживается связь генетических алгоритмов и эволюционной теории (отсюда и характерные термины: популяция, гены, родители-потомки, скрещивание, мутация). Таким образом, существует возможность создания таких нейросетей, которые не были изучены исследователями или не поддаются аналитическому изучению, но тем не менее успешно решают задачу.
Итак, мы установили, что задача распознавания речи может быть решена при помощи нейросетей, причем они имеют все права на конкуренцию с обычными алгоритмами.
3. Самообучающиеся автономные системы
Чем отличается работа, которую выполняют роботы и которую может выполнить человек? Роботы могут обладать качествами, намного превосходящими возможности людей: высокая точностью, сила, реакция, отсутствие усталости. Но вместе с тем они остаются просто инструментами в руках человека. Существует работа, которая может быть выполнена только человеком и которая не может быть выполнена роботами (или необходимо создавать неоправданно сложных роботов). Главное отличие человека от робота – это способность адаптироваться к изменению обстановки. Конечно, практически у всех роботов существует способность работать в нескольких режимах, обрабатывать исключительные ситуации, но все это изначально закладывается в него человеком. Таким образом, главный недостаток роботов – это отсутствие автономности (требуется контроль человека) и отсутствие адаптации к изменению условий (все возможные ситуации закладываются в него в процессе создания). В связи с этим актуальна проблема создания систем, обладающих такими свойствами.
Один из способов создать автономную систему с возможностью адаптации – это наделить её способностью обучаться. При этом в отличие от обычных роботов, создаваемых с заранее просчитанными свойствами, такие системы будут обладать некоторой долей универсальности.
Попытки создания таких систем предпринимались многими исследователями, в том числе и с использованием нейросетей. Один из примеров – созданный в Киевском Институте кибернетики еще в 70-х годах макет транспортного автономного интегрального робота (ТАИР) (см. [6]). Этот робот обучался находить дорогу на некоторой местности и затем мог использоваться как транспортное средство.
Вот какими свойствами, по моему мнению, должны обладать такие системы:
Разработка системы заключается только в построении её архитектуры.
В процессе создания системы разработчик создает только функциональную часть, но не наполняет (или наполняет в минимальных объемах) систему информацией. Основную часть информации система получает в процессе обучения.
Возможность контроля своих действий с последующей коррекцией
Этот принцип говорит о необходимости обратной связи [Действие]-[Результат]-[Коррекция] в системе. Такие цепочки очень широко распространены в сложных биологических организмах и используются на всех уровнях – от контроля мышечных сокращений на самом низком уровне до управления сложными механизмами поведения.
Возможность накопления знаний об объектах рабочей области
Знание об объекте – это способность манипулировать его образом в памяти т.е. количество знаний об объекте определяется не только набором его свойств, но ещё и информацией о его взаимодействии с другими объектами, поведении при различных воздействиях, нахождении в разных состояниях, и т.д., т.е его поведении во внешнем окружении (например, знание о геометрическом объекте предполагает возможность предсказать вид его перспективной проекции при любом повороте и освещении).
Это свойство наделяет систему возможностью абстрагирования от реальных объектов, т.е. возможностью анализировать объект при его отсутствии, тем самым открывая новые возможности в обучении
Автономность системы
При интеграции комплекса действий, которые система способна совершать, с комплексом датчиков, позволяющих контролировать свои действия и внешнюю среду, наделенная вышеприведенными свойствами система будет способна взаимодействовать с внешним миром на довольно сложном уровне, т.е. адекватно реагировать на изменение внешнего окружения (естественно, если это будет заложено в систему на этапе обучения). Способность корректировать свое поведение в зависимости от внешних условий позволит частично или полностью устранить необходимость контроля извне, т.е. система станет автономной.
4. Система распознавания речи как самообучающаяся система
С целью изучения особенностей самообучающихся систем модели распознавания и синтеза речи были объединены в одну систему, что позволило наделить её некоторыми свойствами самообучающихся систем. Это объединение является одним из ключевых свойств создаваемой модели. Что послужило причиной этого объединения?
Во-первых, у системы присутствует возможность совершать действия (синтез) и анализировать их (распознавание), т.е. свойство (2). Во-вторых, присутствует свойство (1), так как при разработке в систему не закладывается никакая информация, и возможность распознавания и синтеза звуков речи – это результат обучения.
Преимуществом полученной модели является возможность автоматического обучения синтезу. Механизм этого обучения описывается далее.
Ещё одной очень важной особенностью является возможность перевода запоминаемых образов в новое параметрическое пространство с гораздо меньшей размерностью. Эта особенность на данный момент в разрабатываемой системе не реализована и на практике не проверена, но тем не менее я постараюсь кратко изложить её суть на примере распознавания речи.
Предположим, входной сигнал задается вектором первичных признаков в N-мерном пространстве. Для хранения такого сигнала необходимо N элементов. При этом на этапе разработки мы не знаем специфики сигнала или она настолько сложна, что учесть её затруднительно. Это приводит к тому, что представление сигнала, которое мы используем, избыточно. Далее предположим, что у нас есть возможность синтезировать такие же сигналы (т.е. синтезировать речь), но при этом синтезируемый сигнал является функцией вектора параметров в M-мерном пространстве, и M<
Далее описывается модель автоматического распознавания и синтеза речи. Описывается механизм ввода звука в нейросеть, модель синтеза речи, модель нейросети, проблемы, возникшие при построении модели.
5.1 Ввод звука
Ввод звука осуществляется в реальном времени через звуковую карту или через файлы формата Microsoft Wave в кодировке PCM (разрядность 16 бит, частота дискретизации 22050 Гц). Работа с файлами предпочтительней, так как позволяет многократно повторять процессы их обработки нейросетью, что особенно важно при обучении.
Для того, чтобы звук можно было подать на вход нейросети, необходимо осуществить над ним некоторые преобразования. Очевидно, что представление звука во временной форме неэффективно. Оно не отражает характерных особенностей звукового сигнала. Гораздо более информативно спектральное представление речи. Для получения спектра используется набор полосовых фильтров, настроенных на выделение различных частот, или дискретное преобразование Фурье. Затем полученный спектр подвергается различным преобразованиям, например, логарифмическому изменению масштаба (как в пространстве амплитуд, так и в пространстве частот). Это позволяет учесть некоторые особенности речевого сигнала – понижение информативности высокочастотных участков спектра, логарифмическую чувствительность человеческого уха, и т.д.
Как правило, полное описание речевого сигнал только его спектром невозможно. Наряду со спектральной информацией, необходима ещё и информация о динамике речи. Для её получения используются дельта-параметры, представляющие собой производные по времени от основных параметров.
Полученные таким образом параметры речевого сигнала считаются его первичными признаками и представляют сигнал на дальнейших уровнях его обработки.
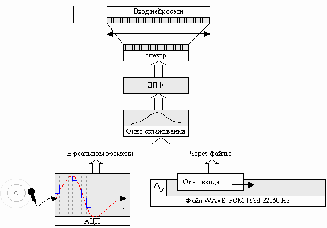
Процесс ввода звуковой информации изображен на рис. 1:
Рис 1. Ввод звука
При обработке файла по нему перемещается окно ввода, размер которого равен размеру окна дискретного преобразования Фурье (ДПФ). Смещение окна относительно предыдущего положения можно регулировать. В каждом положении окна оно заполняется данными (система работает только со звуком, в котором каждый отсчет кодируется 16 битами). При вводе звука в реальном режиме времени он записывается блоками такого же размера.
После ввода данных в окно перед вычислением ДПФ на него накладывается окно сглаживания Хэмминга:
, (1)
N – размер окна ДПФ
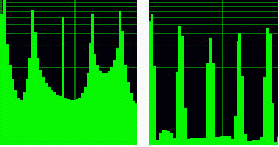
Наложение окна Хэмминга немного понижает контрастность спектра, но позволяет убрать боковые лепестки резких частот (рис 2), при этом особенно хорошо проявляется гармонический состав речи.
без окна сглаживания с окном сглаживания Хэмминга
Рис 2. Действие окна сглаживания Хэмминга (логарифмический масштаб)
После этого вычисляется дискретное преобразование Фурье по алгоритму быстрого преобразования Фурье ([ХХ]). В результате в реальных и мнимых коэффициентах получается амплитудный спектр и информация о фазе. Информация о фазе отбрасывается и вычисляется энергетический спектр:
(2)
Так как обрабатываемые данные не содержат мнимой части, то по свойству ДПФ результат получается симметричным, т.е. E[i] = E[N-i]. Таким образом, размер информативной части спектра NS равен N/2.
Все вычисления в нейросети производятся над числами с плавающей точкой и большинство сигналов ограничены диапазоном [0.0,1.0], поэтому полученный спектр нормируется на 1.00. Для этого каждый компонент вектора делится на его длину:
, (3)
(4)
Информативность различных частей спектра неодинакова: в низкочастотной области содержится больше информации, чем в высокочастотной. Поэтому для предотвращения излишнего расходования входов нейросети необходимо уменьшить число элементов, получающих информацию с высокочастотной области, или, что тоже самое, сжать высокочастотную область спектра в пространстве частот. Наиболее распространенный метод (благодаря его простоте) – логарифмическое сжатие (см. [3], “ Non-linear frequency scales”):
, (5)
f – частота в спектре, Гц,
m – частота в новом сжатом частотном пространстве
5.2 Наложение первичных признаков на вход нейросети
После нормирования и сжатия спектр накладывается на вход нейросети. Входы нейросети не выполняют никаких решающих функция, а только передают сигналы дальше в нейросеть. Выбор числа входов – сложная задача, потому что при малом размере входного вектора возможна потеря важной для распознавания информации, а при большом существенно повышается сложность вычислений (только при моделировании на PC, в реальных нейросетях это неверно, т.к. все элементы работают параллельно).
При большой разрешающей способности (большом числе) входов возможно выделение гармонической структуры речи и как следствие определение высоты голоса. При малой разрешающей способности (малом числе) входов возможно только определение формантной структуры.
Как показало дальнейшее исследование этой проблемы, для распознавания уже достаточно только информации о формантной структуре. Фактически, человек одинаково распознает нормальную голосовую речь и шепот, хотя в последнем отсутствует голосовой источник. Голосовой источник дает дополнительную информацию в виде интонации (изменением высоты тона на протяжении высказывания), и эта информация очень важна на высших уровнях обработки речи. Но в первом приближении можно ограничиться только получением формантной структуры, и для этого с учетом сжатия неинформативной части спектра достаточное число входов выбрано в пределах 50~100.
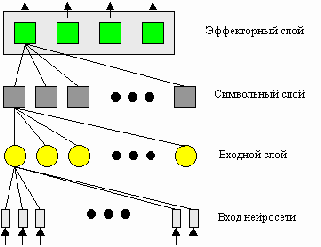
Нейросеть имеет довольно простую структуру и состоит из трех уровней: входной слой, символьный слой и эффекторный слой (рис. 4). Каждый нейрон последующего слоя связан со всеми нейронами предыдущего слоя. Функция передачи во всех слоя линейная, во входном слое моделируется конкуренция.
Рис. 4 Архитектура нейросети
1. Входной слой - этот слой получает сигналы непосредственно от входов нейросети (входы не осуществляют обработку сигнала, а только распределяют его дальше в нейросеть). Он представляет собой один из вариантов самоорганизующейся карты Кохонена, обучающейся без учителя. Основной задачей входного уровня является формирование нейронных ансамблей для каждого класса входных векторов, которые представляют соответствующие им сигналы на дальнейших уровнях обработки. Фактически, именно этот слой определяет эффективность дальнейшей обработки сигнала, и моделирование этого слоя представляет наибольшую трудность.
Нейроны этого слоя функционируют по принципу конкуренции, т.е. в результате определенного количества итераций активным остается один нейрон или нейронный ансамбль (группа нейронов, которые срабатывают одновременно). Этот механизм осуществляется за счет латеральных связей и называется латеральным торможением. Он подробно рассмотрен во многих источниках ([1], [6]). Так как отработка этого механизма требует значительных вычислительных ресурсов, в моей модели он моделируется искусственно, т.е. находится нейрон с максимальной активностью, его активность устанавливается в 1, остальных в 0.
Обучение сети производится по правилу (7):
wн = wс + (x – wс)a, (6)
wн - новое значение веса,
wс – старое значение,
- скорость обучения, <1
x - нормированный входной вектор,
a – активность нейрона.
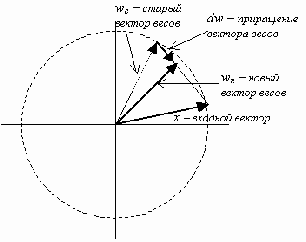
Геометрически это правило иллюстрирует рисунок 5:
Рис. 5. Коррекция весов нейрона Кохонена
Входной вектор x перед подачей на вход нейросети нормируется, т.е. располагается на гиперсфере единичного радиуса в пространстве весов. При коррекции весов по правилу (6) происходит поворот вектора весов в сторону входного вектора. Постепенное уменьшение скорости поворота позволяет произвести статистическое усреднение входных векторов, на которые реагирует данный нейрон.
Проблемы, которые возникают при обучении слоя Кохонена, описаны ниже (см. 5.5)
2. Символьный слой – нейроны этого слоя ассоциированы с символами алфавита (это не обязательно должен быть обычный буквенный алфавит, но любой, например, алфавит фонем). Этот слой осуществляет генерацию символов при распознавании и ввод символов при синтезе. Он представляет собой слой Гроссберга, обучающийся с учителем. Нейрон этого слоя функционирует обычным образом: вычисляет суммарный взвешенный сигнал на своих входах и при помощи линейной функции передает его на выход. Модификация весов связей при обучении происходит по следующему правилу:
wijн = wijс + (yj – wijс)xi, (7)
wijн, wijс – веса связей до и после модификации
- скорость обучения, <1
yj – выход нейрона
xi – вход нейрона
По этому правилу вектор весов связей стремится к выходному вектору, но только если активен вход, т.е. модифицироваться будут связи только от активных в данный момент нейронов слоя Кохонена. Выходы же у символьного слоя бинарные, т.е. нейрон может быть активен (yj = 1) или нет (yj = 0), что соответствует включению определенного символа. Входной слой совместно с символьным слоем позволяют сопоставить каждому классу входных сигналов определенный символ алфавита.
3. Эффекторный слой – этот слой получает сигналы от символьного слоя и также является слоем Гроссберга. Выходом слоя является вектор эффекторов – элементов, активность которых управляет заданными параметрами в модели синтеза. Связь эффекторов с параметрами модели синтеза осуществляется через карту эффекторов. Этот слой позволяет сопоставить каждому нейрону символьного слоя (а следовательно, и каждому символу алфавита) некоторый вектор эффекторов (а следовательно, и определенный синтезируемый звук). Обучение этого слоя аналогично символьному слою.
Обучение нейросети состоит из трех этапов. Сначала системе предъявляется только образцы звуков, при этом во входном слое формируются нейронные ансамбли, ядрами которых являются предъявляемые образцы. Затем предъявляются звуки и соответствующие им символы алфавита. При этом происходит ассоциация нейронов входного уровня с нейронами символьного слоя. На последнем этапе система обучается синтезу. При этом системе не предъявляются никакие образцы, а используется накопленная на предыдущих этапах информация. Используется механизм стохастического обучения: нейроны эффекторного слоя подвергаются случайным изменениям, затем генерируется звук, он распознается и результат сравнивается с тем символом, для которого был сгенерирован звук. При совпадении изменения фиксируются. Этот процесс повторяется до тех пор, пока не будет достигнута правильная генерация всех звуков.
Зачем в правиле обучения слоя Кохонена (6) присутствует коэффициент ? Если бы он был равен 1, то для каждого входного вектора вектор связей активного нейрона приравнивался бы к нему. Как правило, для каждого нейрона существует множество входных сигналов, которые могли бы его активировать, и его вектор связей постоянно менялся бы. Если же <1, на каждый входной сигнал вектор связей реагирует незначительно. Уменьшая в процессе обучения, мы в конце обучения получим статистическое усреднение схожих входных сигналов. С этой же целью вводятся скорости обучения во всех остальных обучающих правилах.
Чем определяется скорость обучения? Здесь главную роль играет порядок предъявления образцов. Допустим, имеется большая обучающая выборка, последовательным предъявлением элементов которой обучается нейросеть. Если скорость обучения велика, то уже на середине этой выборки нейросеть «забудет» предыдущие элементы. А если каждый образец предъявляется подряд много раз, то уже на следующем образце нейросеть забудет предыдущий. Таким образом, главный критерий выбора скоростей обучения – незначительное изменение связей в пределах ВСЕЙ обучающей выборки. Но не следует забывать, что время обучения обратно пропорционально скорости обучения. Так что здесь необходимо искать компромисс.
Запоминание редко встречающихся элементов
Описанный выше алгоритм обучения хорош для часто повторяющихся сигналов. Если же сигнал встречается редко на фоне всей обучающей выборки, он просто не будет запомнен. В таком случае необходимо привлечение механизма внимания [5]. При появлении неизвестного нейросети образца скорость обучения многократно возрастает и редкий элемент запоминается в нейросети. В разрабатываемой системе обучающая выборка строится искусственно, поэтому такой проблемы не возникает, и механизм внимания не реализован. Необходимость механизма внимания появляется при обучении в естественных условиях, когда обучающая выборка заранее не предсказуема.
Проблемы, возникающие при обучении слоя Кохонена
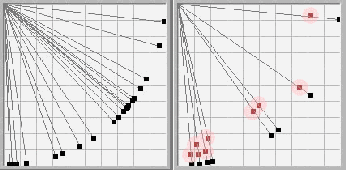
Для исследования динамики обучения и свойств слоя Кохонена был создан инструмент «Модель нейросети», в котором моделируется слой Кохонена в двумерном сигнальном пространстве (Рис 6).
1. Начальные значения весов 2. Веса после обучения
Рис.6. Моделирование слоя Кохонена
В модели создается нейросеть с двумя входами, так что она способна классифицировать входные вектора в двумерном сигнальном пространстве. Хоть функционирование такой нейросети и отличается от функционирования нейросети в сигнальном пространстве с гораздо большей размерностью, основные свойства и ключевые моменты данного нейросетевого алгоритма можно исследовать и на такой простой модели. Главное преимущество – это хорошая визуализация динамики обучения нейросети с двумя входами. В ходе экспериментов с этой моделью были выявлены следующие проблемы, возникающие при обучении нейросети.
1. выбор начальных значений весов.
Так как в конце обучения вектора весов будут располагаться на единичной окружности, то в начале их также желательно отнормировать на 1.00. В моей модели вектора весов выбираются случайным образом на окружности единичного радиуса (рис. 6.1).
2. использование всех нейронов.
Если весовой вектор окажется далеко от области входных сигналов, он никогда не даст наилучшего соответствия, всегда будет иметь нулевой выход, следовательно, не будет корректироваться и окажется бесполезным. Оставшихся же нейронов может не хватить для разделения входного пространства сигналов на классы. Для решения этой проблемы предлагается много алгоритмов ([1],[8]). в моей работе применяется правило «желания работать»: если какой либо нейрон долго не находится в активном состоянии, он повышает веса связей до тех пор, пока не станет активным и не начнет подвергаться обучению. Этот метод позволяет также решить проблему тонкой классификации: если образуется группа входных сигналов, расположенных близко друг к другу, с этой группой ассоциируется и большое число нейронов Кохонена, которые разбивают её на классы (рис. 6.2). Правило «желания работать» записывается в следующей форме:
wн=wc + wс 1 (1 - a), (8)
где wн - новое значение веса,
wс – старое значение,
1 - скорость модификации,
a – активность нейрона.
Чем меньше активность нейрона, тем больше увеличиваются веса связей.
Выбор коэффициента 1 определяется следующими соображениями: постоянный рост весов нейронов по правилу (8) компенсируется правилом (6) (активные нейроны стремятся снова вернуться на гиперсферу единичного радиуса), причем за одну итерацию нейросети увеличат свой вес практически все нейроны, а уменьшит только один активный нейрон или нейронный ансамбль. В связи с этим коэффициент 1 в (8) необходимо выбирать значительно меньше коэффициента в (6), учитывая при этом число нейронов в слое.
3. неоднородное распределение входных векторов в пространстве сигналов и дефицит нейронов.
Очень часто основная часть входных векторов не распределена равномерно по всей поверхности гиперсферы, а сосредоточена в некоторых небольших областях. При этом лишь небольшое количество весовых векторов будет способно выделить входные вектора, и в этих областях возникнет дефицит нейронов, тогда как в областях, где плотность сигнала намного ниже, число нейронов окажется избыточным.
Для решения этой проблемы можно использовать правило «нахождения центра масс», т.е. небольшое стремление ВСЕХ весовых векторов на начальном этапе обучения к входным векторам. В результате в местах с большой плотностью входного сигнала окажется и много весовых векторов. Это правило записывается так:
wн = wс + 2(x – wс). (9)
где wн - новое значение веса,
wс – старое значение,
2 - скорость модификации,
x – входной вектор
Это правило хорошо работает, если нейроны сгруппированы в одном месте. Если же существует несколько групп нейронов, то это правило не дает нужного результата.
Ещё одно решение – использовать «отжиг» весовых векторов. В нашем случае он может быть реализован как добавление небольшого шума при модификации весов, что позволит им перемещаться по поверхности гиперсферы. При обучении уровень шума постепенно понижается, и весовые вектора собираются в местах наибольшей плотности сигнала.
Недостаток этого правила – очень медленное обучение. Если в двумерном пространстве нейроны «находили» входные вектора более-менее успешно, то в многомерном пространстве вероятность этого события существенно снижается.
Самым эффективным решением оказалось более точное моделирование механизма латерального торможения. Как и раньше, находится нейрон с максимальной активностью. Затем искусственно при помощи латеральных связей устанавливается активность окружающих его нейронов по правилу (10):
(10)
aj – активность нейрона
i - выигравший нейрон
j – индекс нейрона
- определяет радиус действия латеральных связей, уменьшается в процессе обучения
При этом предполагается, что все нейроны имеют определенную позицию по отношению к другим нейронам. Это топологическое отношение одномерно и линейно, позиция каждого нейрона определяется его индексом. Правило (10) говорит о том, что возбуждается не один нейрон, а группа топологически близких нейронов. В результате обучения образуется упорядоченная одномерная карта признаков. Упорядоченность означает, что ближайшие два нейрона в ней соответствуют двум ближайшим векторам в пространстве сигнала, но не наоборот (так как невозможно непрерывно отобразить многомерное пространство на одномерное). Сначала радиус действия латеральных связей достаточно большой, и в обучении участвуют практически все нейроны. При этом они находят «центр масс» всей обучающей выборки. В процессе обучения коэффициент уменьшается, нейроны разделяются на группы, соответствующие локальным центрам масс. В конце концов радиус латеральных связей снижается настолько, что нейроны функционируют независимо друг от друга и могут разделять очень близкие вектора.
Разрабатываемая система может применяться как инструмент для проведения исследований в данной предметной области, для демонстрации принципов работы нейросетей и модели синтеза речи.
Список использованных источников
Ф. Уоссермен «Нейрокомпьютерная техника: Теория и практика». Перевод на русский язык Ю. А. Зуев, В. А. Точенов, 1992.
Винцюк Т.К. «Анализ, распознавание и интерпретация речевых сигналов.» -Киев: Наук. думка, 1987. -262 с.
Speech Analysis FAQ - http://svr-www.eng.cam.ac.uk/~ajr/SA95/SpeechAnalysis.html
Л.В. Бондарко «Звуковой строй современного русского языка» -М.: Просвещение, 1997. –175 с.
Э.М.Куссуль «Ассоциативные нейроподобные структуры» -Киев, Наукова думка, 1990
Н.М. Амосов и др. «Нейрокомпьютеры и интеллектуальные роботы» -Киев: Наукова думка, 1991
Г. Нуссбаумер «Быстрое преобразование Фурье и алгоритмы вычисления сверток». Перевод с англ. – М.: Радио и связь, 1985. –248 с.
А.А. Ежов, С.А. Шумский “НЕЙРОКОМПЬЮТИНГ и его приложения в экономике”, - МИФИ, 1998

Нравится материал? Поддержи автора!
Ещё документы из категории информатика:
Чтобы скачать документ, порекомендуйте, пожалуйста, его своим друзьям в любой соц. сети.
После чего кнопка «СКАЧАТЬ» станет доступной!
Кнопочки находятся чуть ниже. Спасибо!
Кнопки:
Скачать документ