Постановка задачі оптимального стохастичного керування
ПОСТАНОВКА ЗАДАЧІ ОПТИМАЛЬНОГО СТОХАСТИЧнОГО КЕРУВАННЯ
1. Загальні положення
Позначатимемо 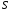 – простір станів,
– простір станів, 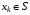 ,
, 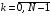 .
.
Можливі керування є множиною припустимих керувань 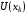 , яка у свою чергу є підмножиною простору керувань
, яка у свою чергу є підмножиною простору керувань 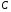 :
: 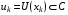 ,
, 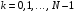 .
.
Послідовність керуючих функцій 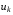 ,
, 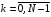 , записана у вигляді
, записана у вигляді
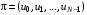 (1),
(1),
називається стратегією керування.
Задача оптимального керування системою (1) полягає в пошуку такої послідовності функцій керування 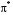 , що мінімізує цільовий функціонал системи за
, що мінімізує цільовий функціонал системи за 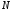 кроків. Ця послідовність називається оптимальною стратегією керування.
кроків. Ця послідовність називається оптимальною стратегією керування.
Визначення. Якщо кількість кроків, на яких досліджується поведінка системи, є скінченною, то задача називається задачею зі скінченним горизонтом рішення. Якщо ж ми розв’язуємо задачу на нескінченному часовому інтервалі (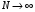 ), то горизонт рішення є нескінченним.
), то горизонт рішення є нескінченним.
Задача оптимального стохастичного керування з дискретним часом випливає із детермінованої задачі, якщо система функціонує за умов випадкових збурень 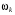 . У цьому випадку функція (1), що визначає стан системи на кожному наступному кроці, залежить від поточного стану
. У цьому випадку функція (1), що визначає стан системи на кожному наступному кроці, залежить від поточного стану 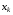 , керування
, керування 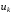 і випадкових збурень :
і випадкових збурень :
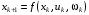 ,
, 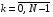 . (2)
. (2)
Збурення є елементами деякого ймовірнісного простору 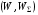 (де
(де 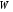 – простір збурень,
– простір збурень, 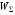 –
– 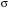 -алгебра підмножин з ) і має розподіл
-алгебра підмножин з ) і має розподіл 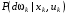 .
.
2 Критерії якості
Розглянемо спочатку критерії якості, які найчастіше використовуються в детермінованих дискретних задачах керування, а потім перейдемо до стохастичного випадку. Якщо на кожному кроці функціонування системи задана функція 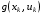 , що визначає витрати за один крок керування, то критерій якості руху матиме вигляд
, що визначає витрати за один крок керування, то критерій якості руху матиме вигляд
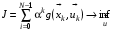 . (3)
. (3)
Величина 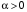 , що називається коефіцієнтом дисконтування, визначає внесок витрат за всі попередні кроки на кожному поточному кроці.
, що називається коефіцієнтом дисконтування, визначає внесок витрат за всі попередні кроки на кожному поточному кроці.
Найчастіше критерій (3) використовується в тих випадках, коли необхідно розв’язувати задачі, пов'язані з витратами деяких видів ресурсів. Саме цей функціонал ми будемо використовувати надалі.
Крім критерію (3) розглядаються також критерії, які мінімізують горизонт системи і є аналогом часу руху для неперервних систем. У цьому випадку цільовий функціонал матиме вигляд
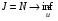 .
.
Також часто в дискретних задачах керування використовуються термінальні функціонали якості
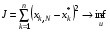 або
або 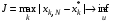 ,
,
де  – заданий стан системи,
– заданий стан системи, 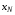 – кінцевий стан системи.
– кінцевий стан системи.
Оскільки в задачі оптимального стохастичного керування збурення 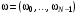 випадкові, то може бути тільки апріорна інформація про них, наприклад, у вигляді функції розподілу, відомої повністю або частково. У цьому випадку якість процесу керування оцінюється за допомогою формули
випадкові, то може бути тільки апріорна інформація про них, наприклад, у вигляді функції розподілу, відомої повністю або частково. У цьому випадку якість процесу керування оцінюється за допомогою формули
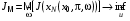 ,
,
яка дорівнює математичному сподіванню функції 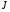 .
.
3 Види функцій керування стохастичною системою
Задача детермінованого керування відрізняється від свого стохастичного аналога тим, що в першій відсутні неконтрольовані фактори , і еволюція системи однозначно визначається обраним керуванням . Отже, у задачі детермінованого керування для кожного початкового стану 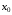 можна заздалегідь вибрати послідовність оптимальних керувань
можна заздалегідь вибрати послідовність оптимальних керувань 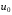 ,
, 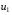 , …,
, …,  , застосування яких дає оптимальне значення функціонала .
, застосування яких дає оптимальне значення функціонала .
Для стохастичної системи в загальному випадку цього зробити не можна, оскільки система переходить зі стану в стан не тільки під дією керування ; на неї на кожному кроці також впливають випадкові величини . Очевидно, що, по-перше, ці величини можуть так змінити траєкторію системи, що обране раніше за оптимальне керування в момент його застосування вже таким не буде, і, по-друге, інформація, одержувана на кожному кроці про впливи , що мали місце, може бути додатково використана для поліпшення якості керування (рис. 1).
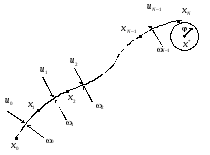
Рисунок 1 – Еволюція стохастичної системи (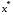 – заданий стан)
– заданий стан)
Отже, для розв’язання задач оптимального стохастичного керування доцільно використовувати стратегії 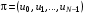 , у яких
, у яких 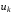 – функція минулих станів системи. У цьому випадку схема визначення оптимального керування на кожному кроці наступна. Якщо
– функція минулих станів системи. У цьому випадку схема визначення оптимального керування на кожному кроці наступна. Якщо 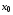 – початковий стан системи, то за перше керування вибирається функція
– початковий стан системи, то за перше керування вибирається функція 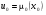 . Якщо мали місце стани , …,
. Якщо мали місце стани , …, 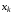 і були задані керування
і були задані керування 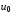 , …,
, …, 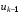 , то керування на
, то керування на  -му кроці вибирається як функція
-му кроці вибирається як функція 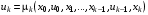 , (
, (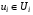 для всіх
для всіх 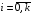 ). Отже, для вибору керування використовується вся інформація, що є в наявності. Описана стратегія керування є позиційною, оскільки керування визначається залежно від реалізованих позицій (станів) системи, на відміну від програмного керування, коли послідовність керувань визначається заздалегідь, до початку процесу керування, і є функцією часу.
). Отже, для вибору керування використовується вся інформація, що є в наявності. Описана стратегія керування є позиційною, оскільки керування визначається залежно від реалізованих позицій (станів) системи, на відміну від програмного керування, коли послідовність керувань визначається заздалегідь, до початку процесу керування, і є функцією часу.
Розглянемо окремі випадки.
Якщо 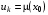 ,
, 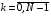 , то керування називається стаціонарним керуванням. Такі стратегії найпростіші, оскільки є одним і тим же вектором для всіх моментів часу.
, то керування називається стаціонарним керуванням. Такі стратегії найпростіші, оскільки є одним і тим же вектором для всіх моментів часу.
Керування  , , називається марковською позиційною стратегією (стратегією, кожний елемент якої залежить тільки від поточного стану системи).
, , називається марковською позиційною стратегією (стратегією, кожний елемент якої залежить тільки від поточного стану системи).
Керування 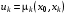 , , називається напівмарковською позиційною стратегією (стратегією, кожний елемент якої залежить тільки від поточного і початкового станів системи).
, , називається напівмарковською позиційною стратегією (стратегією, кожний елемент якої залежить тільки від поточного і початкового станів системи).
Марковські та напівмарковські позиційні стратегії використовуються найчастіше.
Зрозуміло, що в загальному випадку кінцевий стан системи  , згідно з формулою (2)
, згідно з формулою (2)  ,
, 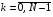 , залежить від початкового стану , керувань
, залежить від початкового стану , керувань 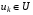 і збурень
і збурень  . Щоб переконатися в цьому, досить виразити в (2) через
. Щоб переконатися в цьому, досить виразити в (2) через 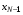 , потім через
, потім через  і т.д. Якщо ці перетворення можливо провести, то одержимо співвідношення
і т.д. Якщо ці перетворення можливо провести, то одержимо співвідношення  . Це означає, що різним реалізаціям випадкового збурення для одного початкового стану
. Це означає, що різним реалізаціям випадкового збурення для одного початкового стану  відповідатимуть різні оптимальні стратегії керування
відповідатимуть різні оптимальні стратегії керування 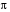 .
.
4 Формальна постановка задачі оптимального стохастичного керування
Розглянемо систему (2) із цільовим функціоналом (3). Надалі, якщо інше не обговорено спеціально, будемо вважати, що оптимальні керування на кожному кроці позиційні: 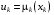 ,
, 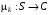 і
і 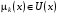 ,
, 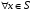 .
.
За таких умов задача оптимального стохастичного керування полягає в пошуку оптимальної послідовності функцій керування 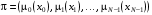 , (тобто стратегії керування), що мінімізує сумарні витрати за увесь час функціонування системи.
, (тобто стратегії керування), що мінімізує сумарні витрати за увесь час функціонування системи.
Формальна постановка задачі оптимального стохастичного керування зі скінченним горизонтом у дискретному випадку має вигляд:
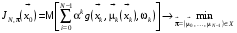 , (4)
, (4)
 . (5)
. (5)
Розв’язання задачі оптимального стохастичного керування з нескінченним горизонтом полягає в пошуку послідовності керувань 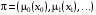 , які мінімізують сумарні витрати.
, які мінімізують сумарні витрати.
Формальна постановка задачі оптимального стохастичного керування з нескінченним горизонтом у дискретному випадку має вигляд:
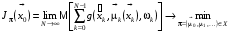 , (6)
, (6)
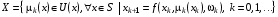 . (7)
. (7)
Далі під час розв’язання задач оптимального керування вважатимемо, що границя у (6) існує для всіх і .
Будемо розглядати задачі (4) – (5) і (6) – (7) у стаціонарному випадку, тобто припускатимемо, що простори станів і керувань і , обмеження керування 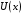 , функція
, функція  і витрати
і витрати 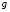 не змінюються при переході від кожного кроку до наступного. Якщо ж це не так, то задача є нестаціонарною. Нестаціонарна задача може бути зведена до стаціонарної за допомогою спеціальних методів, тому далі мова йтиме тільки про стаціонарні задачі.
не змінюються при переході від кожного кроку до наступного. Якщо ж це не так, то задача є нестаціонарною. Нестаціонарна задача може бути зведена до стаціонарної за допомогою спеціальних методів, тому далі мова йтиме тільки про стаціонарні задачі.
Зупинимося детальніше на позначеннях, зроблених вище.
Визначення. Функція 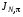 називається функцією витрат за кроків при стратегії
називається функцією витрат за кроків при стратегії  в задачі зі скінченним горизонтом . Аналогом цієї величини для задачі з нескінченним горизонтом є функція
в задачі зі скінченним горизонтом . Аналогом цієї величини для задачі з нескінченним горизонтом є функція 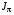 – функція витрат при стратегії .
– функція витрат при стратегії .
Для фіксованого стану 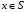 позначимо через
позначимо через 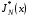 і
і  оптимальні витрати в цих задачах, тобто
оптимальні витрати в цих задачах, тобто
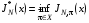 ,
,
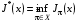 .
.
Якщо останні співвідношення вірні для всіх , то функція 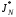 називається оптимальною функцією витрат за кроків, а
називається оптимальною функцією витрат за кроків, а  – оптимальною функцією витрат.
– оптимальною функцією витрат.
Стратегія 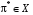 називається оптимальною при горизонті в стані
називається оптимальною при горизонті в стані 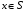 , якщо
, якщо
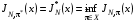 ,
,
і оптимальною в стані , якщо
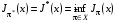 .
.
Стратегія називається оптимальною при горизонті , якщо 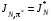 . Це означає, що стратегія доставляє оптимальне значення цільовому функціоналу при всіх .
. Це означає, що стратегія доставляє оптимальне значення цільовому функціоналу при всіх .
Аналогічно, стратегія називається оптимальною, якщо
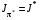 . (8)
. (8)
Стратегія 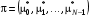 називається рівномірно оптимальною при горизонті , якщо стратегія
називається рівномірно оптимальною при горизонті , якщо стратегія  оптимальна при горизонті
оптимальна при горизонті 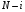 для всіх
для всіх 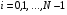 . Отже, якщо стратегія рівномірно оптимальна при горизонті , то вона також оптимальна при горизонті . Зворотне твердження в загальному випадку невірно.
. Отже, якщо стратегія рівномірно оптимальна при горизонті , то вона також оптимальна при горизонті . Зворотне твердження в загальному випадку невірно.
Стратегія 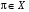 називається стаціонарною стратегією, якщо
називається стаціонарною стратегією, якщо 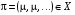 .
.
Якщо у цьому випадку значення цільового функціонала в задачі оптимального стохастичного керування з нескінченним горизонтом отримано з використанням стаціонарної стратегії 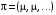 , то результат позначають
, то результат позначають 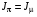 . Отже, стаціонарна стратегія
. Отже, стаціонарна стратегія 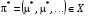 у задачі з нескінченним горизонтом оптимальна, якщо
у задачі з нескінченним горизонтом оптимальна, якщо 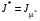 . Тут – оптимальне значення цільового функціонала задачі.
. Тут – оптимальне значення цільового функціонала задачі.
Розв’язання будь-якої задачі оптимального стохастичного керування здійснюється за шість етапів:
1. Змістовна постановка задачі.
2. Побудова моделі об'єкта керування, що включає вибір векторів станів і керувань, просторів станів і керувань, вектора і простору випадкових збурень; побудову функції витрат, що визначається метою керування.
3. Формальна постановка задачі.
4. Вибір і обґрунтування методу розв’язання задачі.
Обчислення оптимальної стратегії керування одним з методів.
6. Аналіз отриманих результатів.
5 Алгоритм розв’язання задачі оптимального стохастичного керування
Процедура пошуку оптимальних позиційних стратегій є досить складною задачею. Одним з головних питань, вирішення якого дозволяє у значній мірі полегшити цю процедуру, є наступне: чи можна обмежитися пошуком оптимальних стратегій у класі стаціонарних або марковских стратегій? Якщо це можливо, то структура керування значно спрощується, і, крім того, зменшується об'єм оброблюваної інформації: не потрібно запам'ятовувати керування 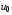 , …,
, …, 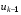 , попередні стани
, попередні стани 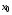 , …,
, …, 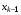 і діставати залежність поточного керування
і діставати залежність поточного керування 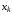 від усіх цих величин. У цьому випадку для розв’язання дискретних задач оптимального керування зі скінченним горизонтом найчастіше використовується алгоритм, заснований на методі динамічного програмування, запропонованого Беллманом. Суть методу полягає в наступному:
від усіх цих величин. У цьому випадку для розв’язання дискретних задач оптимального керування зі скінченним горизонтом найчастіше використовується алгоритм, заснований на методі динамічного програмування, запропонованого Беллманом. Суть методу полягає в наступному:
 , (9)
, (9)
 (10)
(10)
де математичне сподівання береться за мірою 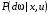 . Формули (9) – (10) є стохастичним аналогом детермінованого алгоритму методу динамічного програмування.
. Формули (9) – (10) є стохастичним аналогом детермінованого алгоритму методу динамічного програмування.
Величина 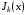 – це оптимальні витрати, пов'язані з функціонуванням системи, за останні кроків, за умови, що перед першим із цих кроків система перебувала в стані
– це оптимальні витрати, пов'язані з функціонуванням системи, за останні кроків, за умови, що перед першим із цих кроків система перебувала в стані 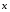 . Стратегія
. Стратегія 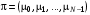 , кожний елемент якої
, кожний елемент якої  доставляє оптимальне значення (10) для всіх ,
доставляє оптимальне значення (10) для всіх ,  , є оптимальною стратегією для кожного
, є оптимальною стратегією для кожного 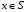 . Оптимальна функція витрат
. Оптимальна функція витрат 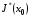 даної задачі визначається на -му кроці і дорівнює
даної задачі визначається на -му кроці і дорівнює 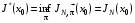 .
.
Для розв’язання задач оптимального стохастичного керування з нескінченним горизонтом, як правило, застосовуються чисельні методи, які дозволяють на кожній ітерації одержувати наближення до оптимального керування і оптимальної функції витрат. У цьому випадку можна показати, що оптимальна функція витрат 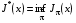 задовольняє рівнянню Беллмана
задовольняє рівнянню Беллмана
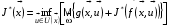 .
.
6 Формулювання задачі оптимального керування в термінах відображень
Сформулюємо задачу оптимального стохастичного керування (4) – (5), а також алгоритм динамічного програмування за допомогою відображення 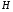 , яке задане формулою:
, яке задане формулою:
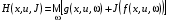 .
.
Розглянемо оператори 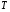 і
і 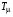 , які відображують множину функцій, що приймають дійсні значення на , в себе:
, які відображують множину функцій, що приймають дійсні значення на , в себе:
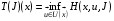 ,
,
 ,
, 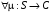 .
.
За таких позначень задачу оптимального стохастичного керування (4) – (5) можна записати у вигляді:
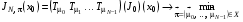 ,
,
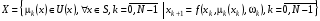 ,
,
де  , , а
, , а 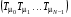 – суперпозиція операторів
– суперпозиція операторів 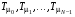 (нагадаємо, що суперпозицією відображень
(нагадаємо, що суперпозицією відображень 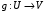 і
і 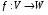 називається відображення
називається відображення 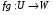 таке, що
таке, що 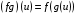 ,
, 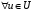 ).
).
Алгоритм динамічного програмування (9) – (10) у термінах відображень можна записати у такий спосіб:
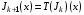 ,
,  ,
,
звідки випливає, що  , де
, де  – -кратний добуток оператора на себе.
– -кратний добуток оператора на себе.
Задачу з нескінченним горизонтом (6)-(7) у термінах відображень
можна сформулювати в такий спосіб.
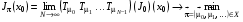 ,
,
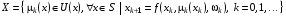 .
.
Функціональне рівняння Беллмана тепер буде еквівалентно рівності
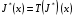 , .
, .

Нравится материал? Поддержи автора!
Ещё документы из категории коммуникации, связь:
Чтобы скачать документ, порекомендуйте, пожалуйста, его своим друзьям в любой соц. сети.
После чего кнопка «СКАЧАТЬ» станет доступной!
Кнопочки находятся чуть ниже. Спасибо!
Кнопки:
Скачать документ