Эволюция корпоративных информационных систем 4

 Хранилища данных
Хранилища данных
(курс лекций)
СОДЕРЖАНИЕ
Введение
Эффективное управление крупным и средним бизнесом сегодня немыслимо без применения передовых информационных технологий — систем поддержки принятия решений (СППР).
Процесс управления сводится к решению 3 задач:
Где мы находимся?
Куда мы хотим прийти?
Как мы туда попадем?
Процесс управления — итерационный характер (принятие решения — применение управляющего воздействия — оценка состояния системы — оценка правильности выбранного решения — при наличии отклонений снова принятие решения).
Современные информационные технологии позволяют аналитику формулировать и решать следующие классы:
Аналитические (вычисление заданных показателей и статистических характеристик).
Визуализация данных
Добыча знаний (data mining —проверка статистических гипотез, кластеризация, нахождение ассоциаций и временных шаблонов и т.п.)
Имитационные (проведение на ЭВМ экспериментов на моделях, описывающих поведение сложных систем, например, в интервалы времени для анализа возможных последствий принятия того или иного решения)
Синтез управления (для определения допустимых управляющих воздействий, обеспечивающих достижение заданной цели, оценка достижимости цели, определение множества возможных управляющих воздействий)
Оптимизационные (интеграция имитационных, управленческих, оптимизационных и статистических методов моделирования и прогнозирования, выбор наиболее эффективного решения).
Однако в настоящее время нет информационных средств для решения всех задач в комплексе.
Бизнес — это сложный объект, который состоит из множества различных по свойствам подсистем, между которыми действует большое число разнородных связей. В кибернетике такие объекты получили название сложных систем, а методы их изучения — системным анализом (эта наука развивается с начала 40-х гг. в период 2-й мировой войны).
Общая с точки зрения теории познания триада имеет вид:
Гипотеза — модель — решение.
Гипотеза — это открытие, которое является новым положением, осуществляется на основе интуиции (из глубин человеческого подсознания, сформированного на основе личного опыта).
По гипотезе строится модель — формальное математическое описание — и находится решение. Полученное решение проверяется в эксперименте (отвергается или принимается). В результате получается знание, которым можно руководствоваться в практике.
Проблемы (в бизнесе):
динамичное изменение экономической ситуации, что мешает применять накопленный опыт, не успевает вырабатываться интуиция.
в условиях свободного рынка нет возможности проводить целенаправленные эксперименты.
В настоящее время актуальна разработка и использование комплексного ПО, реализующего задачи 1, 2 и 3-го классов. Сейчас стремительно развиваются OLAP- технологии.
Сейчас более 100 крупных производителей программ включились в конкуренцию.
OLAP — это инструменты оперативного анализа данных, содержащихся в хранилище, которые предназначены для общения аналитика с проблемой, а не с компьютером.
Эволюция корпоративных информационных систем
Развитие предприятий происходило без стратегического плана, снизу вверх по мере осознания необходимости автоматизации того или иного участка производства.
Условия для автоматизации — появление:
информационных технологий
аппаратно-программных средств
людских ресурсов
бюджетных средств.
В большинстве компаний имеются информационные системы (ИС) на базе СУБД и обслуживают повседневную деятельность отделов компании.
Такие ИС получили название транзакционных или OLТP (On-Line Transactions Processing).
Накопление больших объемов данных в последнее время сделали актуальными прикладные задачи, предназначенные для извлечения, сбора и представления конечному пользователю информации, необходимой для анализа текущего состояния дел и прогноза будущего решения. Такие ИС получили название систем поддержки принятия решений. Исторически первыми такими системами стали ИС руководителя (EIS — Executive Information Systems).
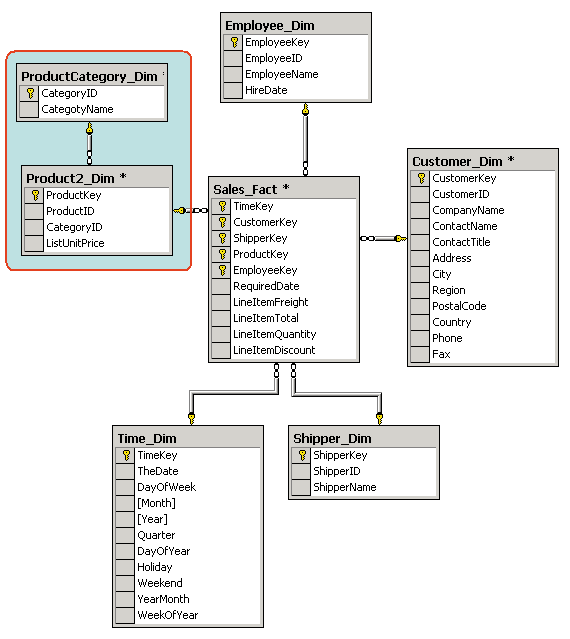
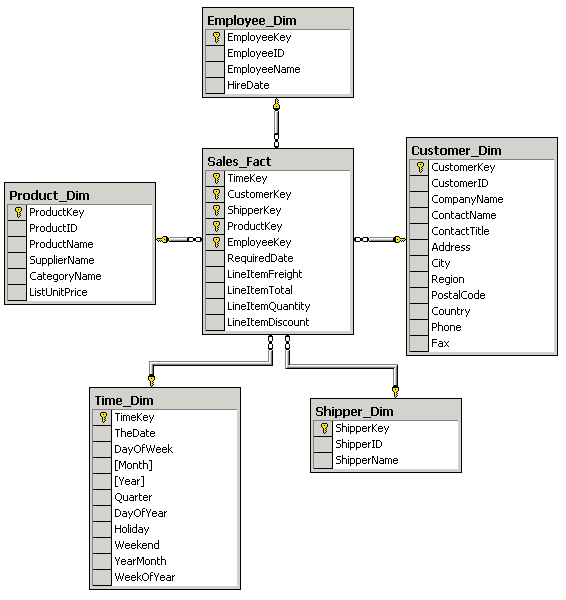
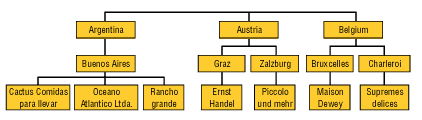
Существует два подхода к интеграции корпоративной информации:
децентрализованное объединение источников (схема спагетти) (рис.1а)
централизованное объединение источников (рис.1б)
(рис.1а) (рис.1б)
Второй подход стимулировал появление технологии хранилищ данных, позволяющей извлекать, преобразовывать и представлять информацию из общей кучи данных.
Основная цель хранилищ — создание единого логического представления данных, содержащихся в разнотипных БД или в единой модели корпоративных данных.
Хранилища данных (Datawarehouse) и оперативный анализ данных (On-LineAnalyticalProcessing, OLAP) – новые информационные технологии, которые обеспечивают аналитикам, управленцам и руководителям высшего звена возможность изучать большие объемы взаимосвязанных данных при помощи быстрого интерактивного отображения информации на разных уровнях детализации с различных точек зрения в соответствии с представлениями пользователя о предметном пространстве.
Еще лет пять назад мало, кто слышал об этих технологиях. Сегодня хранилища данных и OLAP становятся неотъемлемой частью современных корпоративных систем поддержки принятия решений. Это одно из наиболее динамично развивающихся направлений индустрии создания программного обеспечения.
Концепция информационных хранилищ, зародилась в 80-х годах в недрах IBM. Идея хранилищ данных обязана своим развитием многим людям. Хотя эту идею предвосхищали в своих работах многие исследователи, можно смело утверждать, что первой публикацией, посвященной именно хранилищам данных, была статья Девлина (Devlin) и Мэрфи(Murphy) , вышедшая в 1988 году. В 1992 году Уильям Г.Инмон(William H. Inmon), который был техническим директором компании Prism и написал монументальную монографию «Building the Data Warehouse» («Построение хранилищ данных»), в которой дал определение хранилища данных:
Опр.: Хранилище данных — это предметно-ориентированная, интегрированная, вариантная по времени, не разрушаемая совокупность данных, предназначенная для поддержки принятия управленческих решений.
Имеются 2 определения хранилищ данных:
В узком смысле: по Инмону.
В широком:
Хранилище данных — ориентированная на поддержку управленческих решений автоматизированная система, состоящая из организационной структуры, технических средств, базы или совокупности базы данных (БД) и ПО, которое выполняет, как правило, следующие функции:
извлечение данных из разрозненных источников, их трансформация и загрузка в хранилище;
администрирование данных и хранилища;
извлечение данных из хранилища, аналитическая обработка и представление данных конечным пользователям.
Ральф Кимбалл (Ralph Kimball), один из авторов концепции хранилищ данных, описывал хранилище данных как «место, где люди могут получить доступ к своим данным» (см., например, Ralph Kimball, «The Data Warehouse Toolkit: Practical Techniques for Building Dimensional Data Warehouses», John Wiley & Sons, 1996 и «The Data Webhouse Toolkit: Building the Web-Enabled Data Warehouse», John Wiley & Sons, 2000). Он же сформулировал и основные требования к хранилищам данных:
поддержка высокой скорости получения данных из хранилища;
поддержка внутренней непротиворечивости данных;
возможность получения и сравнения так называемых срезов данных (slice and dice);
наличие удобных утилит просмотра данных в хранилище;
полнота и достоверность хранимых данных;
поддержка качественного процесса пополнения данных.
Типичное хранилище данных, как правило, отличается от обычной реляционной базы данных. Во-первых, обычные базы данных предназначены для того, чтобы помочь пользователям выполнять повседневную работу, тогда как хранилища данных предназначены для принятия решений. Например, продажа товара и выписка счета производятся с использованием базы данных, предназначенной для обработки транзакций, а анализ динамики продаж за несколько лет, позволяющий спланировать работу с поставщиками, с помощью хранилища данных.
Во-вторых, обычные базы данных подвержены постоянным изменениям в процессе работы пользователей, а хранилище данных относительно стабильно: данные в нем обычно обновляются согласно расписанию (например, еженедельно, ежедневно или ежечасно — в зависимости от потребностей). В идеале процесс пополнения представляет собой просто добавление новых данных за определенный период времени без изменения прежней информации, уже находящейся в хранилище.
И в-третьих, обычные базы данных чаще всего являются источником данных, попадающих в хранилище. Кроме того, хранилище может пополняться за счет внешних источников, например статистических отчетов.
Учет
Кон-троль
Анализ
Приня-тие решения
Плани-рование
OLAP — это надстройка над OLТP и использует транзакционные системы в качестве источников данных.
В контуре управления взаимосвязаны 5 функций (по кольцу) :
планирование
учет
контроль
анализ
принятие решений.
Рис. 2. Контур управления
2 типа контура:
системы оперативной обработки транзакций
системы класса поддержки принятия решений
Аналитические системы
Транзакционные системы
Руководство
Аппарат управления
Бизнес-аналитики
менеджеры
данные
Рис. 3. Распределение функционала между аналитическими
и транзакционными информационными системами.
Развитие хранилищ данных обусловлено:
созданием развитого ПО оперативного анализа данных и нерегламентированных запросов пользователей;
появлением новых типов БД на основе многомерной модели и параллельной обработки запросов, которые опирались на достижения в области параллельных компьютеров;
появлением ПО промежуточного слоя, обеспечившие связь между разнотипными БД;
резким снижением стоимости хранения информации.
При перенесении данных из оперативной системы в хранилище перед загрузкой они преобразуются. Различного рода несоответствия в кодировании, типах данных и других «свойствах», присущих исходной системе, устраняются. Это также отличный повод для анализа данных исходной системы и приведения в соответствие всех расхождений реального состояния данных с их типами и кодами, представленными в документации. Вообще говоря, построение хранилища данных открывает возможность избавиться от нежелательных «свойств» оперативной системы.
Другим важным свойством, отличающим хранилище данных от оперативной системы, является то, что оно не разрушается. В то время как оперативная система выполняет над хранимыми данными операции обновления, удаления и вставки, в хранилище помещается большой объем данных, которые, будучи раз загруженными, уже никогда более не подвергаются каким-либо изменениям. Конечно, редкие исключения из этого правила бывают. Характерной особенностью хранилища данных является то, что два разных корпоративных пользователя, выполняющие один и тот же запрос к хранилищу данных в разное время, получат один и тот же результат. Это исключает ситуации, при которых незапланированное извлечение данных и генерация отчетов приводят к различным результатам.
Еще одна особенность хранилища данных – независимость от времени. Если оперативная система содержит только текущие данные, то системы хранилищ данных содержат как исторические данные, так и данные, которые имели статус текущих при последней загрузке хранилища. Временные рамки данных, содержащихся в хранилище, изменяются в широких пределах в зависимости от типа системы. Однако обычно временные рамки данных, находящихся в хранилище, лежат в пределах от 15-ти месяцев до пяти лет. Данные большей давности, как правило, переносятся в архив на магнитной ленте или CDROM, если, конечно, их присутствие в хранилище данных больше не требуется.
Системы оперативных данных и информационные системы на основе хранилищ данных обладают рядом противоположных характеристик, которые лучше всего сравнивать непосредственно одну с другой. В таблице 1.1. приведен краткий перечень основных свойств систем каждого типа.
Таблица 1.1. Сравнительные характеристики хранилищ данных и оперативных систем
Системы хранилищ данных
Оперативные системы
Используются руководством
Используются работниками «переднего края»
Стратегическое значение
Тактическое значение
Поддерживают стратегические направления развития бизнеса
Поддерживают повседневную деятельность
Используются для интерактивного анализа
Используются для обработки транзакций
Предметно-ориентированные
Ориентированны на приложения
Хранят исторические данные
Хранят только текущие данные
Непредсказуемые запросы
Предсказуемые запросы
В настоящее время хранилища данных построены для столь большого числа предметных областей, что их невозможно здесь перечислить. Масштабы и способ использования этих хранилищ данных изменяются в широких пределах в зависимости от типа организации и вида деловой информации, для поддержки которых они разрабатывались. Вот некоторые из наиболее распространенных областей применения хранилищ данных.
Анализ рисков.
Финансовый анализ.
Анализ случаев мошенничества.
Маркетинг взаимоотношений.
Управление активами.
Анализ стереотипов поведения клиентов.
Общие свойства хранилищ
Хранилище данных создается с целью интеграции в одном месте, согласования и, возможно, агрегации ранее разъединенных детализированных данных:
Исторических архивов
Данных из оперативных систем
Данных из внешних источников
Разделения наборов данных, используемых для оперативной обработки, и наборов данных, используемых для решения задач поддержки принятия решений.
Обеспечения всесторонней информационной поддержки максимальному кругу пользователей.
Хранилище данных играет в первую очередь роль интегратора и аккумулятора исторических данных. Структура организации хранилища ориентированна на предметные области. Предметно-ориентированное хранилище содержит данные, поступающие из различных оперативных БД и внешних источников. Хранилище представляет собой совокупность данных, отвечающую следующим характеристикам:
ориентированность на предметную область или ряд предметных областей,
интегрированность,
зависимость от времени (поддержка хронологии),
постоянство.
Ориентированность на предметную область
Первая особенность хранилища данных заключается в его ориентированности на предметный аспект. Предметная направленность контрастирует с классической ориентированностью прикладных приложений на функциональность и процессы.
Приложения всегда оперируют функциями, такими, например, как открытие сделки, кредитование, выписка накладной, зачисление на счет и т.д. Хранилище данных организовано вокруг фактов и предметов, таких, как сделка, сумма кредита, покупатель, поставщик, продукт и т.д.
Интегрированность
Наиболее важный аспект хранилища данных состоит в том, что данные, находящиеся в хранилище, интегрированы.
Интегрированность проявляется во многих аспектах:
в согласованности имен,
в согласованности единиц измерения переменных,
в согласованности структур данных,
в согласованности физических атрибутов данных и др.
Контраст между интеграцией данных в хранилище данных и в прикладном окружении иллюстрируется следующим образом.
Первая причина возможного рассогласования приложений заключается в наличии множества средств разработки. Каждое средство разработки диктует определенные правила, часть из которых индивидуальна для данного средства. Не секрет, что каждый разработчик предпочитает одни средства разработки другим. Если два разработчика используют различные средства разработки, они, как правило, применяют индивидуальные особенности средств, а значит, возникает вероятность несогласованности между создаваемыми системами.
Вторая причина возможного рассогласования приложений заключается в существовании множества способов построения приложения. Способ построения конкретного приложения зависит от стиля разработчика, от времени, когда это приложение разрабатывалось, а также от ряда факторов, характеризующих конкретные условия разработки приложения. Все это отражается на используемых способах задания ключевых структур, способах кодирования, обозначения данных, физических характеристиках данных и т.д. Таким образом, если два разработчика создают различные способы построения приложений, имеется высокая вероятность того, что полной согласованности между системами не будет.
Интеграция данных по единицам измерения атрибутов состоит в следующем. Разработчики приложений к вопросу о способе задания размеров продукции могут подходить несколькими путями. Размеры могут задаваться в сантиметрах, дюймах, ядрах и т.д. Каков бы ни был источник данных, если информация поступит в хранилище, она должна быть приведена к одним и тем же единицам измерения, принятым в качестве стандарта в хранилище.
Зависимость от времени
Все данные в хранилище в определенный момент времени совместны (непротиворечивы). Для оперативных систем эта базовая характеристика данных соответствует совместности данных в момент доступа. Когда в оперативной среде осуществляется доступ к данным, ожидается, что данные имеют совместные значения только в момент доступа к ним.
Зависимость от времени хранилища данных проявляется в следующем. Данные в хранилище представлены за временной промежуток от года до 10 лет. В оперативной среде представление данных осуществляется в промежутке от текущего значения до нескольких десятков дней. Приложения с высокой производительностью для обеспечения эффективного процесса транзакций должны работать с минимальным количеством данных. Следовательно, оперативные приложения ориентированны на короткий временной промежуток.
Другое проявление зависимости хранилища данных от времени заключается в его структуре. Каждая структура хранилища включает – явно или неявно – элемент времени.
Третье проявление зависимости хранилища данных от времени состоит в неукоснительном выполнении правила, что данные, однажды корректно в хранилище записанные, не могут быть обновлены. Хранилище данных с точки зрения практического использования представляет собой большую серию моментальных снимков. Естественно, если моментальный снимок данных был сделан некорректно, он может быть изменен. Но если был получен корректный моментальный снимок, то, однажды сделанный, он в последующем изменению не подлежит. Оперативные данные, будучи корректны в момент доступа к ним, могут обновляться по мере необходимости.
Постоянство
Четвертая определяющая характеристика хранилища данных – это постоянство. В оперативной среде операции обновления, добавления, удаления и изменения производятся над записями регулярно. Базовые манипуляции с данными хранилища ограничены начальной загрузкой данных и доступом к ним. В хранилище данных обновление данных не производится. Исходные (исторические) данные, после того как они были согласованны, верифицированы и внесены в хранилище данных, остаются неизменными и используются исключительно в режиме чтения.
Существуют важные последствия различия обработки данных в оперативной среде и обработки в хранилище данных. На уровне проектирования хранилища данных необходимость в поддержке механизмов, обеспечивающих корректность обновлений, отпадает – обновления в хранилище данных не производятся. Это означает, что на физическом уровне проектирования при решении проблемы нормализации и физической денормализации доступ к данным может оптимизироваться без каких-либо ограничений. Другое последствие простоты работы с данными хранилища касается технологии работы с данными. Технология работы с данными в оперативной среде отличается большей сложностью. Она поддерживает функции оперативного резервного копирования и восстановления, обеспечивает целостность данных, включает механизмы разрешения конфликтов и тупиковых ситуаций. Для обработки информации в хранилище данных указанные функции не столь критичны.
Характеристики хранилища данных – ориентированность на предметную область при проектировании, интегрированность данных, зависимость от времени и простота управления данными – определяют среду, которая существенно отличается от классической транзакционной среды.
Источником почти всех данных среды хранилища данных являются оперативные среды. Может возникнуть ощущение, что существует огромная избыточность данных в обеих средах. Однако на практике избыточность данных в средах минимальна, поскольку:
При передаче данных из оперативной среды в хранилище данных эти данные фильтруются. Многие данные вообще никогда не выгружаются из оперативной среды. В хранилище данных передается только информация, используемая для обработки в системе поддержки принятия решений.
Временной горизонт в средах существенно различается. Данные в оперативной среде всегда являются текущими. Данные в хранилище имеют хронологию. С точки зрения временного горизонта пересечение между оперативной средой и средой хранилища данных минимально.
Хранилище данных содержит агрегированные (итоговые) данные, которые никогда не включаются в оперативную среду.
Передача данных из оперативной среды в хранилище данных сопровождается фундаментальными преобразованиями. Большинство данных при поступлении в хранилище видоизменяется.
Данные хранилища
В общем случае модель данных современных Систем Поддержки Принятия Решений (СППР) строится на основе пяти классов данных:
источники данных,
хранилища данных (в узком смысле),
оперативный склад данных,
витрины данных,
метаданные.
Источники данных
Источниками данных хранилища служат оперативные транзакционные системы, которые обслуживают повседневную учетную деятельность компании. Необходимость включения той или иной транзакционной системы в качестве источника определяется бизнес-требованиями к СППР. Исходя из этих же требований, в качестве источников данных, могут быть рассмотрены внешние системы, в том числе и Интернет. Детальные данные из источников могут либо напрямую поступать в хранилище, либо предварительно агрегироваться до требуемого уровня обобщения.
Хранилище данных (в узком смысле)
Хранилище данных (в узком смысле) представляет собой предметно-ориентированную базу или совокупность БД, извлекаемых из источников, которые организованы по сегментам, отражающим конкретную предметную область бизнеса: производство, правило, детальные слабо агрегированные данные.
Оперативный склад данных (Operational Data Store - ODS)
В литературе существуют разные определения этого класса данных. В частности под оперативным складом данных можно подразумевать технологический элемент хранения данных в СППР, который служит буфером между транзакционными источниками данных и хранилищем. Как было уже отмечено ранее, данные, прежде чем попасть в хранилище, должны быть преобразованы в единые форматы, очищены, объединены и синхронизированы. Например, данные, необходимые для поддержки принятия решения, могут существовать в транзакционной системе более короткое время (часы, дни), чем период пополнения данных хранилища (дни, недели). Или семантически однородные данные поступают из транзакционных систем в разное время. В этом случае оперативный склад данных служит аккумулятором данных, поступающих от источников, перед их загрузкой в хранилище. В отличие от хранилища данных информация в складе данных может изменяться со временем в соответствии с изменениями, происходящими в источниках данных.
Оперативный склад данных создается как промежуточный буфер между оперативными системами и хранилищем данных. Эта конструкция, аналогичная конструкции хранилища данных. Идентичность оперативного склада и хранилища данных состоит в их предметной ориентированности и хранении детальных данных. Отличие от хранилища данных состоит в том, что оперативный склад данных:
имеет изменяемое содержимое,
содержит только детальные данные,
содержит текущие значения данных.
Детальные данные — это данные из оперативных и внешних систем, не подвергавшиеся операциям обобщения, суммирования, т.е. данные, не изменившие своей семантики. Из оперативных систем и внешних источников данные поступают в оперативный склад, проходя процессы трансформации.
Данные оперативного склада регулярно обновляются. Каждый раз, когда данные изменяются в оперативных системах и внешних источниках, соответствующие им данные из оперативного склада также должны быть изменены. Частота обновления оперативного склада зависит как от частоты обновления источников, так и от регламента загрузки данных в склад.
Витрины данных (Data mart)
Функционально ориентированные витрины данных представляют собой структуры данных, обеспечивающие решение аналитических задач в конкретной функциональной области или подразделении компании, например управление прибыльностью, анализ рынков, анализ ресурсов и проч. Иногда эти структуры хранения данных называют также киосками данных. Витрины данных можно рассматривать как маленькие хранилища, которые создаются с целью информационного обеспечения аналитических задач конкретных управленческих подразделений компании.
Как правило, витрина содержит значительно меньше данных, охватывает всего несколько предметных областей и имеет более короткую историю. Витрины данных можно представить в виде логически или физически разделенных подмножеств хранилищ данных. Обычно они строятся для обслуживания нужд определенной группы пользователей.
Источником данных для витрин служат данные хранилища, которые, как правило, агрегируются и консолидируются по различным уровням иерархии. Детальные данные могут также помещаться в витрину или присутствовать в ней в виде ссылок на данные хранилища.
Различные витрины данных содержат разные комбинации и выборки одних и тех же детализированных данных хранилища. Важно, что данные витрины поступают из центрального хранилища данных — единого "источника истины".
Метаданные
Метаданные — это любые данные о данных. Метаданные играют важную роль в построении Систем Поддержки Принятия Решений (СППР). Одновременно это один из наиболее сложных и недостаточно практически проработанных объектов. В общем случае можно выделить по крайней мере три аспекта метаданных, которые должны присутствовать в системе.
С точки зрения пользователей:
метаданные для бизнес-аналитиков,
метаданные для администраторов,
метаданные для разработчиков.
С точки зрения предметных областей:
структуры данных хранилища,
модели бизнес-процессов,
описания пользователей,
технологические и пр.
С точки зрения функциональности системы:
метаданные о процессах трансформации,
метаданные по администрированию системы,
метаданные о приложениях, метаданные о представлении данных
пользователям.
Присутствие трех перечисленных аспектов метаданных подразумевает, что, например, прикладные пользователи и разработчики системы будут иметь различное видение технологических аспектов трансформации данных из источников: прикладные пользователи - семантику, состав и периодичность пополнения хранилища данными из источника, разработчики - ER-диаграммы, правила трансформации и интерфейс доступа к данным источника.
В настоящее время отсутствует единая промышленная технология проектирования, создания и сопровождения метаданных. Поэтому вопросы, связанные с управлением метаданными, рассматриваются отдельно, применительно к каждому конкретному проекту построения СППР.
Компоненты хранилища
Хранилище на самом верхнем уровне состоит, как правило, из трех подсистем:
подсистемы загрузки данных,
подсистемы обработки запросов и представления данных,
подсистемы администрирования хранилища.
Подсистема загрузки данных
Данная подсистема представляет собой ПО, которое в соответствии с определенным регламентом извлекает данные из источников и приводит их к единому формату, определенному для хранилища. Данная подсистема отвечает за формализованную логическую согласованность, качество и интеграцию данных, которые загружаются из источников в оперативный склад данных. Каждый источник данных требует разработки собственного загрузочного модуля. Каждый модуль должен решать два класса задач:
Начальной загрузки ретроспективных данных,
Регламентного пополнения хранилища данными из источников.
Данная подсистема также по регламенту извлекает детальные данные из оперативного склада, производит их агрегирование, консолидацию, трансформацию и помещает данные в хранилище и витрины данных. Именно в данной подсистеме должны быть определены все бизнес-модели консолидации данных по иерархическим измерениям и вычисления зависимых бизнес-показателей по независимым исходным данным.
Подсистема обработки запросов и представления данных
Оперативный склад, хранилище и витрины данных являются инфраструктурой, которая обеспечивает хранение и администрирование данных. Для извлечения данных, их аналитической обработки и представления конечным пользователям служит специальное ПО. Как правило, можно выделить три типа данного ПО:
Программное обеспечение регламентированной отчетности, которое характеризуется заранее предопределенными запросами данных и их представлениями бизнес-пользователям. От данного ПО не требуется быстрого времени реакции. Из соображений стоимости эффективности для его реализации в наибольшей степени подходит технология ROLAP (см. далее).
Программное обеспечение нерегламентированных запросов пользователей. Это ПО – основной способ общения бизнес-аналитиков с хранилищем, при котором каждый последующий запрос к данным и вид их представления определяются, как правило, результатами предыдущего запроса. Для приложений данного типа требуется высокая скорость обработки запросов (единицы секунд). Данное ПО реализуется технологией MOLAP (см. далее) и специальными инструментами построения сложных нерегламентированных запросов с интуитивно понятным для бизнес-аналитиков графическим интерфейсом.
Программное обеспечение добычи знаний, которое реализует сложные статистические алгоритмы и алгоритмы искусственного интеллекта, предназначенные для поиска скрытых в данных закономерностей, представления этих закономерностей, представления этих закономерностей в виде моделей и многовариантного прогнозирования по ним развития ситуаций по схеме «Что если …?».
Конечно, как правило, такое деление носит весьма условный характер, а границы между соответствующими приложениями могут быть размыты [2].
Подсистема администрирования хранилища
К ведению данной подсистемы относятся все задачи, связанные с поддерживанием системы и обеспечением ее устойчивой работы и расширения. Можно выделить, по крайней мере, четыре класса задач, расширение которых должна обеспечивать данная подсистема:
Администрирование данных, которое включает в себя регулярное пополнение данных из источников, если необходимо, ручной ввод, сверка и корректировка данных в оперативном складе. Администрирование данных ведется, как правило, бизнес-пользователями, а ответственность распределяется по предметно-ориентированным сегментам.
Администрирование хранилища данных. В задачу администрирования хранилища входят все вопросы, связанные с поддержанием архитектуры хранилища, его эффективной и бесперебойной работы, защитой и восстановлением данных после сбоев.
Администрирование доступа к данным обеспечивает сопровождение профилей пользователей, разграничение доступа к конфиденциальным данным, защиту информации от несанкционированного доступа.
Администрирование метаданных системы.
Методика (методология) построения хранилищ данных
Существуют различные подходы к стратегии построения корпоративного хранилища данных (ХД):
построение сверху вниз,
снизу вверх,
динамическая интеграция данных и др.
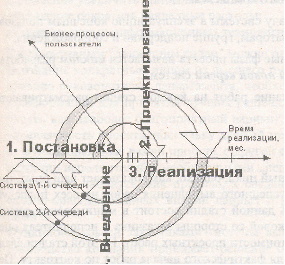
Считается, что наиболее эффективным подходом является подход, при котором в процессе разработки и внедрения хранилища данных осуществляется его пошаговое наращивание на основе единой системы классификаторов и общей среды передачи и хранения данных – спиральная модель процесса разработки.
постановка
задачи
проекти-
рование
реализация
внедр-
ение
постановка задачи
проектирование
реализация
внедрение
постановка
задачи
проекти-
рование
реализация
внедр-
ение
Рис. 4а. Спиральная модель разработки
Рис. 4б. Стратегия построения СППР
На каждом шаге развертывания осуществляется реализация одной или ограниченного числа витрин данных по следующему технологическому циклу (стадиям создания):
постановка задачи,
проектирование,
реализация,
внедрение.
Стратегия пошагового наращивания позволяет по завершении каждого цикла ввести в кратчайшие сроки в промышленную эксплуатацию законченную систему, с определенной ограниченной функциональностью. Небольшие масштабы каждого проектного цикла существенно уменьшают потери при возможных проектных ошибках по сравнению с полномасштабным проектированием и созданием системы в целом. Кроме того, поскольку в каждом цикле применяются одни и те же методологические и технологические подходы, а также средства разработки, то время реализации каждой новой витрины будет сокращаться за счет повышения опыта проектной группы и постепенной отладки механизма взаимодействия между заказчиком и разработчиком системы.
Постановка задачи
Системно-аналитическое обследование
Этап обследования начинается с согласования и утверждения заказчиком плана и программы обследования. В процессе обследования выполняются следующие виды работ:
проводятся интервью с основными участниками проекта со стороны компании-заказчика и лицами, ответственными за принятие управленческих решений;
уточняется организационная структура, фиксируются организационные и функциональные рамки проекта;
выявляются и документируются особенности и недостатки существующих информационных решений;
формализуется схема бизнеса компании с учетом функциональных рамок;
производится сбор существующих отчетных материалов и прочих официальных документов, имеющих непосредственное отношение к реализации проекта.
По итогам обследования уточняются стратегические и оперативные задачи управления компанией, решение которых должна обеспечивать СППР, формализуются цели и задачи создания системы. Цель этапа анализа – получение моделей данных и описание процедур принятия управленческих решений.
Техническое задание
Техническое задание (ТЗ) – один из ключевых документов проекта, который определяет требования к созданию СППР и порядок этого создания. Как правило, если время разработки системы превышает двенадцать месяцев, то целесообразно вводить очередность и, соответственно, сначала разрабатывать на основе концепции ТЗ систему первой очереди, которая может быть реализована за 3 месяца. В противном случае динамично развивающиеся условия бизнеса, постоянно совершенствующиеся информационные технологии приведут к тому, что, когда полномасштабная система будет реализована, она уже морально устареет. Если проект достаточно масштабен, то помимо основного ТЗ на систему в целом могут разрабатываться и частные ТЗ на ее отдельные компоненты.
Проектирование
На данной стадии проектных работ, на основе анализа требований к системе, сформулированных в ТЗ, разрабатываются основные архитектурные решения. Архитектура информационной системы рассматривается в четырех аспектах:
Логическая архитектура. Представляет архитектуру системы с точки зрения пакетов базовых классов и их взаимосвязей. Определяются автоматизируемые процессы и функции, необходимые для достижения поставленных целей, которые затем разделяются на задачи, подлежащие реализации на стадии разработки.
Архитектура процессов. Применительно к СППР, определяет информационное обеспечение системы – состав и содержание процессов преобразования и передачи данных.
Компонентная архитектура. Представляет архитектуру ПО системы, ее декомпозицию на подсистемы и компоненты.
Техническая архитектура. Описывает физические узлы системы и связи между ними.
Автоматизируемые процессы и функции
Система Поддержки Принятия Решений (СППР) по виду автоматизированной ЭШтельности относятся к системам обработки и передачи информации. Объектами автоматизации являются технические процессы, связанные с информационным обеспечением управленческой и аналитической деятельности руководящего персонала и специалистов подразделений и высшего руководства компании. Целями системы являются:
Интеграция ранее разъединенных детализированных данных:
O исторических архивов,
O данных из оперативных систем,
O данных из внешних источников.
Разделение наборов данных, используемых для оперативной обработки, и наборов данных, используемых для решения задач поддержки принятия решений.
Обеспечение всесторонней информационной поддержки максимальному кругу ЭШезователей.
Для реализации поставленных целей в рамках системы подлежат автоматизации следующие процессы:
Сбор данных.
Преобразование данных:
O Очистка данных.
O Согласование данных.
O Унификация данных.
O Агрегирование данных.
Хранение данных:
O Промежуточное хранение данных.
O Накопление исторических данных.
Предоставление данных потребителям.
Сопровождение метаданных.
Информационное обеспечение
В общем случае информационное обеспечение системы состоит из пяти классов данных:
источников данных,
оперативного склада данных,
хранилища данных,
витрины данных,
репозитария метаданных.
Проектирование информационного обеспечения системы осуществляется сверху вниз. На основе анализа прецедентов использования системы, выявленных на этапе системно-аналитического обследования, определяются представления данных конечным прикладным пользователям системы: состав показателей и их разрезы. Осуществляется сегментация представлений данных в соответствии с их проблемной ориентацией. На основе групп представлений витрин должны быть определены:
Измерения, их иерархии и уровень детализации. Например, для временного измерения должен быть определен минимальный интервал времени (день, неделя, месяц), по которому будут индексироваться показатели в витрине.
Базовые показатели, измерения, их индексирующие, и правила агрегирования каждого показателя по иерархиям. Правила агрегирования по иерархическому измерению зависят от показателя. Например, если для дохода от продаж агрегирование по времени осуществляется простым суммированием, то при исследовании цены продукции агрегирование по времени может быть реализовано в виде среднего, максимального или минимального значения за период агрегации.
Производные показатели и формулы их вычисления на основе базовых показателей.
Выбор конкретного способа представления витрин (ROLAP, MOLAP или HOLAP — см. далее) выполняется, как правило, на стадии реализации системы.
Выявленные измерения и показатели служат исходными данными для проектирования хранилища.
В первую очередь обобщаются все выявленные разрезы и их иерархии. На их основе проектируется бизнес-пространство хранилища. Измерения, как правило, тесно связаны со структурированной нормативно-справочной информацией компании. Например, измерениями хранилища часто служат организационная структура компании, справочник административно-территориального деления, план финансовых статей компании и пр.
На пространстве, которое задается бизнес-измерениями, проектируются базовые и производные показатели, которые должны находиться в хранилище. Для больших систем целесообразно проводить сегментацию хранилища по предметным областям.
На следующем этапе выполняется анализ результатов обследования источников данных. При выборе подходящего источника во внимание принимаются следующие вопросы:
Если имеется более одного источника, следует ли определить, какой из них лучше?
Какие преобразования необходимо выполнить, чтобы приготовить источник к загрузке в хранилище?
Согласуются ли структура источника и структура хранилища?
Насколько согласуются данные источника с нормативно-справочной информацией?
Что будет происходить, если источник имеет несколько месторасположений?
Насколько аккуратны данные источника?
Как источник обновляется?
Каковы возраст и перспективность источника?
Насколько полны данные?
Что потребуется для интеграции данных источника в поток загрузки?
Какова технология хранения данных в источнике?
Насколько эффективно может осуществляться доступ к источнику?
На основе выполненного анализа принимаются следующие архитектурные решения:
Определяются состав, содержание и источники потоков данных, которые будут поступать из источников в хранилище.
Определяются преобразования, которые должны быть выполнены над данными при загрузке, а также периодичность загрузки данных в хранилище.
При необходимости проектируются структуры оперативного склада данных и транзитных файлов.
Выявляются данные, которые отсутствуют в источниках информационного хранилища. Для таких данных, как правило, проектируются процедуры и регламенты ручного ввода.
Общая структура репозитария хранилища является своего рода отражением главной цели его построения, а именно максимально полно и быстро удовлетворить потребности пользователей в той или иной информации. В зависимости от потребностей пользователей в информации можно выделить следующие ее основные типы:
Персональную информацию – эта информация, используемая пользователями со строго определенными обязанностями и информационными потребностями. Обычно требует большой предварительной обработки, или, другими словами, имеет высокий уровень агрегации. Чаще всего храниться в МБД.
Информацию по бизнес-темам – информация, относящаяся к определенной тематике, например, как финансовая деятельность организации. Для организаций имеющих близкие функциональные и организационные структуры, ее можно определить как информацию для подразделения (например, для финансовой службы). Имеет более широкий спектр, как в предметных областях, так и вовремени, но вместе с тем напрямую используется реже, чем персонализированная информация. Обычно храниться в смешанных структурах: МБД и реляционных таблицах.
Детальные данные – самая подробная информация, доступная в хранилище данных. Обычными пользователями применяется весьма редко, только в случае необходимости подробного уточнения информации. Обычно является полем деятельности аналитиков по добыче знаний (или поиску скрытых зависимостей в больших объемах информации). Обычно храниться в реляционных структурах.
Старые детальные данные – это, по сути, тот же самый низкий уровень агрегирования, что и у текущих детальных данных, - выделяются в особый тип по следующей причине. С одной стороны, старые детальные данные часто требуют больших ресурсов для хранения, а с другой – они со временем, например, через несколько лет, необходимы очень редко. Решением в данном случае является использование более дешевых и емких способов хранения, например лент или библиотек.
Компонентная архитектура
Система на самом верхнем уровне состоит, как правило, из двух видов ПО: общего и специального.
К общему ПО относятся:
ПО промежуточного слоя, которое обеспечивает сетевой доступ к приложениям и БД. Сюда относятся сетевые и коммуникационные протоколы, драйверы, системы обмена сообщениями и пр.
ПО загрузки и предварительной обработки данных. Этот уровень включает в себя набор средств для загрузки данных из OLTP-систем и внешних источников. Проектируется, как правило, в сочетании с дополнительной обработкой: проверкой данных на чистоту, консолидацией, форматированием, фильтрацией и пр.
Серверное ПО. Представляет собой ядро всей системы. Оно включает в себя:
Серверы реляционных БД,
Серверы МБД,
Серверы приложений (поисковые, аналитической обработки, добычи знаний и др.).
Специальное ПО представляет собой совокупность программ, разрабатываемых при создании Систем Поддержки Принятия Решений (СППР). Они объединяются в следующие подсистемы:
Подсистему загрузки данных,
Подсистему обработки запросов и представления данных,
Подсистему администрирования.
В этой части должны быть спроектированы модули, составляющие подсистему, и алгоритмы отдельных процедур, входящих в их состав.
Техническая архитектура
Серверное ПО работает под управлением серверов приложений и серверов БД на UNIX- или NT-платформах или мэйнфреймах. Клиентское ПО, устанавливается на ПК конечных пользователей. В последние годы наметилось стремительное внедрение технологии «тонкого» клиента, при которой на ПК пользователя находится лишь Web-броузер, а вся функциональность клиентского ПО загружается с сервера приложений в виде JavaScript- программ или апплетов. Техническая архитектура во многом зависит от масштабови требований, предъявляемых к ее производительности и надежности. В зависимости от этого серверные компоненты системы могут располагаться на одном компьютере или на нескольких. Сегменты хранилища и витрины данных в больших системах могут располагаться на нескольких компьютерах.
Реализация
Данная стадия проекта непосредственно связана с разработкой и тестированиемкомпонентов информационного и специального ПО системы в соответствии с разработанной на этапе проектирования архитектурой.
К основным результатам работы на этом этапе следует отнести:
Непосредственно саму систему в виде общего и специального ПО, баз данных.
План внедрения системы, который должен определять все работы по внедрению системы у заказчика, включая упаковку системы, доставку ее заказчику, инсталляцию системы на технических средствах заказчика, тестирование и доработку.
Набор тестов, которые должны быть выполнены после установки системы у заказчика.
Пользовательскую документацию и учебные материалы для пользователей системы.
Внедрение
Данная фаза состоит в выполнении работ, предусмотренных планом внедрения, который был разработан на предыдущей фазе.
На стадии развертывания осуществляются монтаж и установка системы и отдельных ее компонентов у заказчика. Осуществляется первоначальная загрузка хранилища необходимыми данными, выполняется опытная эксплуатация системы. Кроме того, на стадии развертывания осуществляется обучение пользователей и сотрудников службы технической поддержки. Окончанием данного этапа считается момент перехода к производственной эксплуатации хранилища.
Выбор метода реализации Хранилищ данных
Продукция Microsoft
Фирма Microsoft твердо убеждена, что ее продукты позволяют значительно усовершенствовать процесс создания хранилища данных. Она разработала продукт DataWarehousing Framework, в котором объединены различные технологии (доступ к данным, метаданные, преобразования, запрос конечного пользователя и т.д.) во всех ЭШлах построения и использования хранилища данных, а также управления им. Фирма Microsoft, кроме того, обеспечила поддержку каждого компонента Warehousing Network в продуктах Microsoft Office, BackOffice и Visual Studio. Microsoft тесно сотрудничает и с другими фирмами – производителями продуктов разработки хранилища данных с целью создания Data Warehousing Alliance. Все эти фирмы работают на основе общих технологий и протоколов, которые были установлены для Warehousing Framework. Это позволяет повысить совместимость и возможность взаимодействия различных продуктов на рынке технологий создания хранилищ данных [8].
В СУБД MicrosoftSQLServer 7.0 предусмотрено много средств, которые могут помочь в построении хранилища данных. Поддержка больших баз данных, оптимизация запросов и репликация — все эти функции делают SQLServer мощным инструментом для создания хранилища или витрины данных (рис. 5). Гетерогенные запросы позволяют объединить результирующие наборы из нескольких источников данных OLEDB или ODBC. Кроме того, к вашим услугам службы преобразования данных (DTS), склад (Repository) для хранения метаданных, OLAP-средства для принятия решений (DecisionSupportServices) и MicrosoftEnglishQuery (выполнение запросов на английском языке) [10].
SQL Server
MicrosoftDecisionSupportServices
MicrosoftEnglishQuery
OLE DB
ODBS
DTS
REPOSITORY
Рис. 5. Схема работы с хранилищем данных при помощи продукции Microsoft
Службы преобразования данных (DataTransformationServices – DTS) – это универсальный набор инструментов, встроенный в SQLServer 7.0. Он позволяет легко импортировать, экспортировать и преобразовывать данные, перемещая их между любыми двумя источниками, которые поддерживают OLEDB. В каком-то смысле DTS — это своего рода насос данных, с помощью которого можно перемещать исходные записи с одного места на другое с помощью простого интерфейса мастера.
В DTS предусмотрены службы импорта и экспорта данных из различных источников:
источников данных, поддерживающих OLEDB: Oracle, SQLServer 4.2, 6.5 и др.;
источников данных, поддерживающих ODBC: DB2 на MVS, данных AS400, Informix, MicrosoftAccess, MicrosoftExcel и др.;
текстовых ASCII-файлов, содержащих поля фиксированной длины или разделенных символами-ограничителями.
Приложение MicrosoftRepository — это инфраструктура для хранения и совместного использования метаданных. Оно позволяет простым способом описывать данные, находящиеся в хранилище. С помощью склада информационные структуры данных можно хранить отдельно от самих данных; к этим структурам также можно обращаться из других компонентов архитектуры хранилища данных. Склад хранилища данных обладает следующими возможностями:
сохраняет модели данных со звездообразной структурой;
заносит в каталог связи между элементами данных и исходными СУБД;
регистрирует преобразования данных и родословные данных:
сохраняет правила выборки данных и репликации;
поддерживает работу команды разработчиков.
Службы поддержки принятия решений фирмы Microsoft (MicrosoftDecisionSupportServices) — это инструменты, позволяющие сделать общедоступными возможности OLAP и информацию, находящуюся в хранилище. С их помощью можно представить информацию из хранилища в виде многомерных кубов, что способствует проведению анализа данных.
Главные особенности и преимущества MicrosoftDSS:
доступ к любому поддерживающему OLEDB источнику данных;
поддержка MOLAP (многомерной интерактивной аналитической обработки), ROLAP (реляционной OLAP) и HOLAP(гибрида первых двух);
объединение возможностей хранения данных SQLServer и анализа данных Excel путем поддержки средств создания свободных таблиц;
возможность проведения анализа данных в автономном режиме, например во время передвижения в автомобиле, самолете и т.д.
возможность перехода от настольной системы к общей модели для всего предприятия.
Продукция Sybase
Adaptive Server IQ – это СУБД, оптимизированная для анализа данных на уровне физического дизайна. Уникальная архитектура IQ позволяет обрабатывать незапланированные аналитические запросы в десятки-сотни раз быстрее, чем традиционные СУБД. При этом вместо разбухания данных в хранилище происходит их сжатие [7].
СУБД Sybase Adaptive Server IQ специально разработана для высокоскоростного анализа данных. Благодаря использованию передовой технологии обработки запросов, уникальных способов индексирования и алгоритмов, оптимизирующих производительность, удалось увеличить скорость выполнения нерегламентированных запросов более чем в 100 раз по сравнению с традиционными CУБД и поддерживать производительность, несмотря на увеличение числа пользователей и на изменение типов запросов в зависимости от потребностей бизнеса. В отличие от технологий традиционных СУБД, Adaptive Server IQ обеспечивает отличную производительность без интенсивной настройки (рис. 6).
PowerDesigner® WarehouseArchitect™
СУБД Sybase Adaptive Server IQ Multiplex
Sybase Warehouse Studio
Warehouse Control Center
Infomaker
Sybase PowerStage
REPOSITORY
Рис. 6. Схема работы с хранилищем данных при помощи продукции Sybase
Технологии Adaptive Server IQ обеспечивают высокую скорость анализа данных, гибкость и экономичность одновременно с эффективной поддержкой большого количества пользователей. Sybase Adaptive Server IQ обеспечивает высокие показатели в таких областях как:
Быстрота:
oМолниеносная скорость выполнения запросов благодаря патентованному, ориентированному на столбцы, методу хранения данных и революционным технологиям индексирования;
oБыстрая параллельная загрузка.
Гибкость:
oПоддержка запросов любой сложности.
oПростота интеграции в гетерогенные системы за счет открытой архитектуры любой схемы.
oПоддержка широкого спектра платформ (Sun, HP, IBM, SGI, NT).
Экономичность:
oСжатие данных от 15% до 40%.
oМасштабируемость – поддержка от десятков до тысяч пользователей.
oНе требует настройки, низкая стоимость обслуживания.
oВозможность построения эффективных решений для организации хранилищ на недорогих платформах.
Обычно для управления очень большими объемами информации используются традиционные реляционные базы данных, хранящие данные построчно. Традиционные СУБД хорошо приспособлены для использования в системах оперативной обработки данных (OLTP), где важен быстрый доступ к конкретной строке и частая модификация данных. В случае работы с системами поддержки принятия решений (DSS), нет необходимости работы со всей строкой целиком, так как большинство бизнес задач требует от нас работы только с определенным набором полей. В этом случае чтение всей строки влечет неоправданную затрату ресурсов и значительно усложняет или делает невозможным одновременную работу большого количества пользователей со сверхбольшими базами данных VLDB. Кроме того, с ростом объема исходных данных в традиционных СУБД происходит неуправляемое увеличение объемов хранилища, что требует сложного, дорогостоящего сопровождения и администрирования.
Sybase Adaptive Server IQ Multiplex использует особый, ориентированный на столбцы, метод хранения данных. Такой подход в сочетании с новыми индексными технологиями, преодолевающими ограничения традиционных индексов, значительно ЭШеляет процесс выполнения запросов и снижает требования к объему дискового пространства. Благодаря этому Sybase Adaptive Server IQ Multiplex обеспечивает доступ тысячам ЭШезователей к терабайтным хранилищам данных по цене намного меньшей, чем у конкурентов. Технологии Sybase Adaptive Server IQ Multiplex обеспечивают практически неограниченную масштабируемость при простоте и низкой стоимости внедрения и обслуживания.
Применение режима Multiplex позволяет легко создавать кластерные решения на базе обычных серверов, что позволяет повысить отказоустойчивость и эффективнее использовать ресурсы хранилища.
Ниже приведены несколько технических характеристик Adaptive Server IQ 12.
Корпоративная производительность
oСкорость выполнения запросов в 10 – 100 раз выше, чем для традиционных реляционных СУБД;
oСкорость загрузки с полной индексацией составляет до 40 ГБ/час.
Открытость и совместимость
oПоддержка SQL 95 и Sybase Т-SQL;
oВозможность локализации;
oХранимые Java процедуры и пользовательские функции.
Операционная гибкость
oДинамическое обновление для обеспечения круглосуточной работы;
oПолное управление транзакциями;
oПоддержка NT и UNIX.
Наименьшие расходы на содержание из всех серверов систем поддержки принятия решении
oСжатие данных в отношении 5:1 по сравнению с традиционными PСУБД;
oНевысокие требования к памяти;
oНевысокие требования к сопровождению и обучению;
oЛегкость настройки.
Неограниченная масштабируемость
oОт сотен до тысяч пользователей;
oСохранение высокой производительности при работе с данными, объемом превышающим 280 триллионов записей и 16 000 полей;
oЭкономичная поддержка сверхбольших баз данных – объемом до 128 ТБ данных;
oВозможности мультиплексирования – Multiplex.
Независимость от источников данных
oИнтегрированная поддержка Oracle, Informix, Microsoft, DB2, Teradata, AS/400, VSAM, и других систем.
Также Sybase обладает и своим инструментальным средством для построения хранилищ данных — . Данное ПО значительно упрощает процесс разработки и обслуживания хранилища. В комплект входят: Warehouse Architect — CASE-средство проектирования хранилища, Warehouse Control Center — средство управления метаданными и администрирования хранилища, Infomaker — генератор отчетов и пр.
Sybase Warehouse Studio — это открытая среда для проектирования хранилищ данных и управления метаданными, которая упрощает процесс разработки и обслуживания хранилища, одновременно предоставляя небывалую гибкость в выборе серверных платформ для хранилища и приложений для Бизнес-Анализа. Warehouse Studio — это мощный инструмент для быстрой разработки бизнес-приложений, приносящий реальный результат, как с точки зрения бизнеса, так и с точки зрения времени и технологии.
Достоинства Sybase Warehouse Studio:
Ключ к быстрой разработке – этот комплект инструментов для проектирования и управления хранилищем данных, направленный на максимально быстрое получение результата как в области технологии, так и в бизнес-области;
Широкая поддержка РСУБД – поддерживаются все основные серверы ЭШеляонных баз данных, включая Oracle, Microsoft SQL Server, Informix, DB2 и Sybase;
Интегрированность — концепция технологии Warehouse Studio – дать разработчику единый простой инструмент для работы с хранилищами данных;
Простой доступ для пользователей – средства управления метаданными позволяют конечным пользователям как просматривать содержание каталога хранилища, так и строить свои собственные запросы, используя популярные бизнес-приложения для анализа и построения отчетов, такие как Cognos, Brio, Business Objects, English Wizard;
Глобальное управление метаданными — Warehouse Studio включает инструменты для импорта, синхронизации и использования метаданных, позволяющие управлять единым каталогом метаданных всех хранилищ и витрин данных предприятия.
На начальном этапе, проектировании, Warehouse Studio предлагает PowerDesigner® WarehouseArchitect™, позволяя графически спроектировать практически все детали будущего хранилища. В последующем WarehouseArchitect позволяет сгенерировать sql-скрипты для загрузки хранилища данных и даже передать необходимую информацию бизнес-приложению таким образом, чтобы пользователи могли немедленно приступить к работе с хранилищем. Поддерживая различные схемы дизайна: реляционную, многомерную, «звезда», «снежинка», WarehouseArchitect предоставляет эффективный инструмент для построения хранилища любого уровня сложности.
Наличие мощного механизма генерации отчетов позволяет в любой момент иметь качественную документацию модели и удобный доступ к специфическим объектам хранилища: фактам, размерностям, внешним таблицам, атрибутам, метрикам и многомерным кубам.
Начиная с дизайна хранилища и заканчивая вводом его в эксплуатацию, Warehouse Control Center™ позволяет импортировать, синхронизировать, администрировать и использовать логические и физические метаданные обо всех хранилищах и витринах данных предприятия, размещая их в центральном репозитарии.
Для управления процессом импорта, преобразования и загрузки данных Warehouse Studio эффективно интегрируется с лидером рынка Sybase PowerStage. Информация PowerStage о схеме преобразования данных может импортироваться в репозитарий метаданных Warehouse Control Center.
Продукция Oracle
Направление хранилищ данных и аналитических систем является сегодня для компании Oracle одним из самых приоритетных. Будучи поставщиком полного технологического решения в данной области, Oracle выпускает новые продукты и постоянно совершенствует существующие.
В общем виде, технология функционирования любой корпоративной ЭШеляяионно-аналитической системы состоит в следующем. Данные поступают из различных внутренних транзакционных систем, от подчиненных структур, от внешних организаций в соответствии с установленным регламентом, формами и макетами отчетности. Вся эта информация проверяется, согласуется, преобразуется и помещается в хранилище и витрины данных. После этого пользователи с помощью специализированных инструментальных средств получают необходимую им информацию для построения различных табличных и графических представлений, прогнозирования, моделирования и выполнения других аналитических задач [3].
В соответствии с этим основными функциями информационно-аналитической системы являются:
Извлечение данных из различных источников, их преобразование и загрузка в хранилище
Хранение данных
Анализ данных, включая регламентированные отчеты, произвольные запросы, многомерный анализ (OLAP) и извлечение знаний (data mining).
Обычно для выполнения этих функций используются различные продукты, что приводит к усложненной архитектуре системы, необходимости интегрировать разнородные инструментальные среды, дополнительным затратам на администрирование, проблемам согласования данных и метаданных на различных серверах.
Корпорация Oracle предлагает новый подход к созданию аналитических систем – единую и функционально полную платформу для решения всех перечисленных задач[4].
Основой решения является система управления базами данных Oracle9i Database, с помощью которой можно не только надежно хранить огромные объемы аналитической информации, но и эффективно выполнять процедуры извлечения данных из разнородных источников, согласовывать, агрегировать и преобразовывать эти данные в аналитическую информацию, загружать ее в хранилище. Кроме того, средствами этого же продукта поддерживаются различные методы анализа данных, включая многомерный анализ, прогнозирование, поиск закономерностей. Все эти функции реализуются описанными ниже специальными компонентами Oracle9i:
Компонент Data Warehousesобъединяет те возможности сервера Oracle, которые предназначены для построения и эффективного использования хранилищ данных. Режимы функционирования базы данных для аналитических задач требуют специальных настроек параметров, методов индексирования и обработки запросов. Начиная с Oracle7, в СУБД Oracle стали появляться новые средства, с помощью которых совершенствовалась работы базы в режиме хранилищ и витрин данных. К их числу относятся параллельная обработка запросов, позволяющая наиболее полно использовать возможности многопроцессорных аппаратных платформ, эффективные битовые (bitmap) индексы и специализированные алгоритмы выполнения запросов, такие как хэш-соединения (hash joins), которые многократно повысили производительность обработки аналитических запросов. В СУБД Oracle имеется мощная возможность секционирования данных (partitioning), облегчающая управление и значительно ускоряющая обработку очень больших таблиц и индексов. Кроме того, появились новые схемы оптимизации, преобразующие запросы к типу «звезда», что позволяет избежать ресурсоемкого полного соединения справочных таблиц. Одним из важнейших усовершенствований в этом же направлении является технология управления суммарными данными на основе материализованных представлений (materialized views). Анализируя статистику работы системы, СУБД рекомендует администратору необходимые агрегаты, автоматически их создает и периодически обновляет. Затем при выполнении запросов с агрегированием система автоматически переписывает их таким образом, чтобы они обращались к суммарным данным, хранящимся в материализованных представлениях. Такой подход резко, иногда на несколько порядков, повышает производительность хранилища данных для конечных пользователей. Среди других технологий, связанных с быстродействием в аналитических задачах, — функциональные индексы, специальные операции для вычисления итогов и подитогов в отчетах, широкий спектр встроенных аналитических функций и ряд других.
ETL компонент — это расширение стандартных средств СУБД Oracle дополнительными командами и средствами, полезными для задач сбора и преобразования данных. К таким средствам относятся внешние таблицы, автоматическая фиксация изменения данных (change data capture), табличные функции, одновременный ввод и корректировка данных, ввод данных в несколько таблиц и др. [5].
Опция OLAP Services позволяет хранить и обрабатывать многомерную информацию на том же сервере баз данных, где находится реляционное хранилище. По функциональным возможностям OLAP Services сравнимы с многомерной СУБД OracleExpress и по существу завершают процесс интеграции технологии OracleExpress с реляционным сервером OracleDatabase. Средства OLAP Services поддерживают в полном объеме основной язык сервера Express, а для существующих баз данных Express обеспечивается их миграция в СУБД Oracle [6].
Средствами опции Oracle9i DataMining реализуется технология data mining, с помощью которой в больших объемах информации можно автоматически выявить ЭШелямерность и взаимосвязи, полезные для принятия управленческих решений.
Концепция построения систем поддержки принятия решений, предлагаемая Oracle, объединяет все компоненты, необходимые для создания и управления Хранилищем Данных, а также для использования накопленной в нем информации.
На рис.7. представлен набор программных средств Oracle, реализующих вышеперечисленные задачи.
Oracle9i
Oracle Express
ETL
OLAP Services
Data Warehouses
REPOSYTORY
Oracle Reports
Application Server
JDeveloper
BI JavaBeans
Database
Data Mining
Oracle Warehouse Builder
Data Warehouses Method (DWM)
Server
Рис. 7. Набор программных средств Oracle, реализующих технологию работы с ХД
Для разработки и развертывания хранилищ и витрин данных предназначен продукт Oracle Warehouse Builder, который представляет собой интегрированную CASE-среду, ориентированную на создание информационно-аналитических систем. Средствами этого продукта можно проектировать, создавать и администрировать хранилища и витрины данных, разрабатывать и генерировать процедуры извлечения, преобразования и загрузки данных из различных источников, эффективно управлять метаданными. Стандарты Common Warehouse Model, лежащие в основе репозитария Oracle Warehouse Builder, обеспечивают его интеграцию с различными аналитическими инструментальными средствами как Oracle, так и других фирм. Для организации доступа с рабочих мест аналитиков к данным хранилища и витрин используются специализированные рабочие места, поддерживающие необходимые технологии как оперативного, так и долговременного анализа. Аналитическая деятельность в рамках корпорации достаточно разнообразна и определяется характером решаемых задач, организационными особенностями компании, уровнем и степенью подготовленности аналитиков. В связи с этим современный подход к инструментальным средствам анализа не ограничивается использованием какой-то одной технологи. В настоящее время принято различать четыре основных вида аналитической деятельности:
стандартная отчетность,
нерегламентированные запросы,
многомерный анализ (OLAP) и
извлечение знаний (data mining).
Каждая из этих технологий поддерживается продуктами Oracle: для стандартной отчетности используется OracleReports, для формирования нерегламентированных отчетов и запросов — OracleDiscoverer, для сложного многомерного анализа – опция сервера Oracle9i OLAP Services вместе с Jdeveloper и BI JavaBeans или линия продуктов OracleExpress, а для задач «извлечения знаний опция OracleDataMining.
Важнейшей чертой аналитических инструментальных средств и приложений Oracle является их готовность к работе в среде Web. Менеджеры и аналитики, где бы они ни находились, могут получать информацию из Хранилищ и Витрин Данных в защищенной Интранет-архитектуре с помощью сервера приложений Oracle9i ApplicationServer.
Кроме собственно продуктов, обеспечивающих полное решение для корпоративной информационно-аналитической системы, корпорация Oracle предлагает оригинальную методологию выполнения проекта по созданию и сопровождению таких систем. Эта методология называется Data Warehouse Method (DWM) и является частью общего подхода Oracle к проектированию и реализации различных проектов.
Выбор продукта
Для успешного внедрения Хранилища Данных крайне важен правильный выбор поставщика. Предлагаемое им решение должно удовлетворять следующим критериям:
Полнота — решение должно покрывать бизнес-потребности компании, предлагать полный спектр программных продуктов, обеспечивать техническую поддержку, обучение и другие сервисные услуги. Помимо технологической основы, оно должно включать в себя готовые приложения, которые позволят менеджерам решать вышеупомянутые аналитические задачи – поиска возможностей роста, обеспечения финансовой эффективности и баланса между ними.
Интегрированность — решение должно хорошо вписаться в существующую среду; оно должно обеспечить бесперебойное взаимодействие всеми между компонентами системы на основе стандартов, принятых в индустрии программного обеспечения.
Неограниченность — решение должно быть адаптируемым к изменениям; оно должно быть расширяемым на большее количество пользователей и большие объемы данных.
Гарантированность — решение должно быть проверенным в смысле получаемых бизнес-преимуществ и качества технологии; поставщик должен иметь прочные финансовые позиции, значительную долю рынка, хорошую клиентскую базу и большое число партнеров, внедряющих его технологии.
Выбирая Oracle, организация получает решение, удовлетворяющие всем этим критериям. Оно включает в себя как интегрированный набор программных продуктов, поддерживающих полный цикл построения и эксплуатации Хранилища Данных, так и комплекс связанных с этим услуг. Продукты Oracle характеризуются высокой степенью ЭШештабируемости, работают на большинстве аппаратных платформ и с любыми источниками информации. Таким образом, можно создать аналитическую систему в любой среде и адаптировать ее к возможным изменениям. Наконец, все это уже не однажды сделано: на базе технологий Oracle внедрены тысячи систем поддержки принятия решений по всему миру, в том числе на территории СНГ [9].
По данным аналитической фирмы IDC Research на начало 2001 года, компания Oracle, крупнейший производитель программного обеспечения для электронного бизнеса, лидирует на рынке инструментального ПО для хранилищ данных (на долю компании приходится 21% этого рынка объемом 5,3 миллиардов долларов).
IDC уверена, что ПО хранилищ данных помогает компаниям повысить эффективность своего бизнеса и реализовать новые возможности. Хотя своему лидерству на рынке инструментального ПО для хранилищ данных Oracle обязана главным образом доминированию на рынке систем управления базами данных (СУБД) в целом, корпорация в то же время является одним из ведущих поставщиков средств доступа к информации хранилищ данных.
Отчет IDC охватывает три сегмента рынка инструментального ПО для хранилищ данных: средства управления, средства доступа к информации и средства генерации хранилищ данных. В 1999 году совокупный доход от продаж ПО этого типа во всем мире достиг 5,3 миллиардов долларов, а к 2004 году IDC прогнозирует его рост до 17 миллиардов долларов. Из трех указанных сегментов рынка два — средства управления хранилищами данных и средства доступа к информации — выросли в 1999 году по сравнению с 1998 годом особенно заметно: на 22,4 и на 38,6% соответственно. На рынке средств управления хранилищами данных Oracle лидировала в 1999 году почти с 10%-ным отрывом от ближайшего конкурента.
На развивающемся рынке хранилищ данных и интеллектуального бизнес-ПО лидерство от мелких поставщиков с узкой специализацией переходит к таким компаниям, как Oracle, способным предложить полное, комплексное решение. Отчет IDC подтверждает бесспорное лидерство Oracle на рынке инструментального ПО для хранилищ данных.
Комплекс инструментального ПО Oracle, решающий весь спектр задач интеллектуального электронного бизнеса, основан на открытых интерфейсах, поддерживающих Эмые разные приложения Oracle и независимых производителей. С помощью таких компонентов Oracle9i Application Server, как Oracle Discoverer и OracleReports, бизнес-аналитики выполняют сложные запросы и анализируют данные — и реляционные, и многомерные, публикуя затем отчеты в интра- и экстрасетях. В целом весь комплекс интеллектуальных бизнес-инструментов Oracle сокращает расходы на разработку и внедрение хранилищ данных и служит мощным средством анализа, без которого невозможно успешное развитие любого предприятия.
Что такое OLAP
Системы поддержки принятия решений обычно обладают средствами предоставления пользователю агрегатных данных для различных выборок из исходного набора в удобном для восприятия и анализа виде. Как правило, такие агрегатные функции образуют многомерный (и, следовательно, нереляционный) набор данных (нередко называемый гиперкубом или метакубом), оси которого содержат параметры, а ячейки — зависящие от них агрегатные данные1. Вдоль каждой оси данные могут быть организованы в виде иерархии, представляющей различные уровни их детализации. Благодаря такой модели данных пользователи могут формулировать сложные запросы, генерировать отчеты, получать подмножества данных.
Технология комплексного многомерного анализа данных получила название OLAP (On-Line Analytical Processing). OLAP — это ключевой компонент организации хранилищ данных. Концепция OLAP была описана в 1993 году Эдгаром Коддом, известным исследователем баз данных и автором реляционной модели данных (см. E.F. Codd, S.B. Codd, and C.T.Salley, Providing OLAP (on-line analytical processing) to user-analysts: An IT mandate. Technical report, 1993). В 1995 году на основе требований, изложенных Коддом, был сформулирован так называемый тест FASMI (Fast Analysis of Shared Multidimensional Information — быстрый анализ разделяемой многомерной информации), включающий следующие требования к приложениям для многомерного анализа:
предоставление пользователю результатов анализа за приемлемое время (обычно не более 5 с), пусть даже ценой менее детального анализа;
возможность осуществления любого логического и статистического анализа, характерного для данного приложения, и его сохранения в доступном для конечного пользователя виде;
многопользовательский доступ к данным с поддержкой соответствующих механизмов блокировок и средств авторизованного доступа;
многомерное концептуальное представление данных, включая полную поддержку для иерархий и множественных иерархий (это — ключевое требование OLAP);
возможность обращаться к любой нужной информации независимо от ее объема и места хранения.
Следует отметить, что OLAP-функциональность может быть реализована различными способами, начиная с простейших средств анализа данных в офисных приложениях и заканчивая распределенными аналитическими системами, основанными на серверных продуктах. Но прежде чем говорить о различных реализациях этой функциональности, давайте рассмотрим, что же представляют собой кубы OLAP с логической точки зрения.
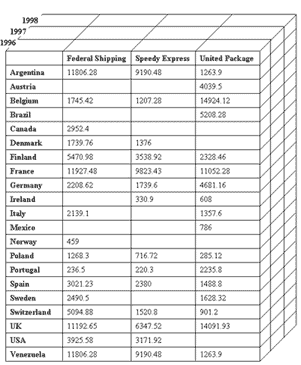
Многомерные кубы
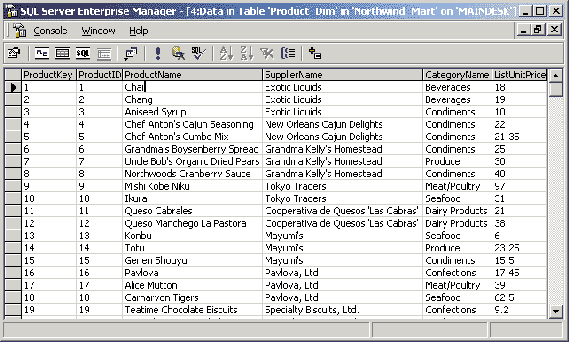
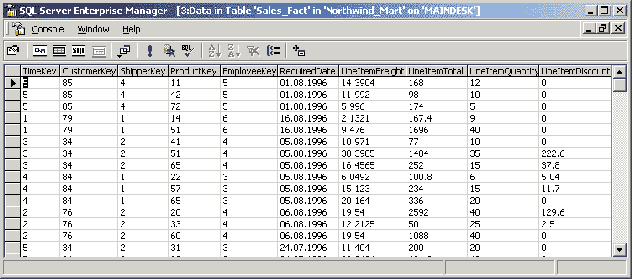
В данном разделе мы более подробно рассмотрим концепцию OLAP и многомерных кубов. В качестве примера реляционной базы данных, который мы будем использовать для иллюстрации принципов OLAP, воспользуемся базой данных Northwind, входящей в комплекты поставки Microsoft SQL Server или Microsoft Access и представляющей собой типичную базу данных, хранящую сведения о торговых операциях компании, занимающейся оптовыми поставками продовольствия. К таким данным относятся сведения о поставщиках, клиентах, компаниях, осуществляющих доставку, список поставляемых товаров и их категорий, данные о заказах и заказанных товарах, список сотрудников компании. Подробное описание базы данных Northwind можно найти в справочных системах Microsoft SQL Server или Microsoft Access — здесь за недостатком места мы его не приводим.
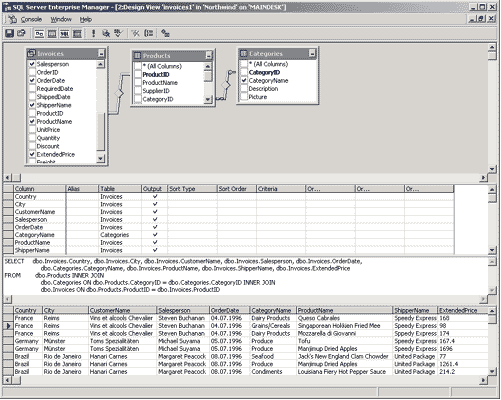
Для рассмотрения концепции OLAP воспользуемся представлением Invoices и таблицами Products и Categories из базы данных Northwind, создав запрос, в результате которого получим подробные сведения о всех заказанных товарах и выписанных счетах:
SELECT dbo.Invoices.Country,
dbo.Invoices.City,
dbo.Invoices.CustomerName,
dbo.Invoices.Salesperson,
dbo.Invoices.OrderDate,
dbo.Categories.CategoryName,
dbo.Invoices.ProductName,
dbo.Invoices.ShipperName,
dbo.Invoices.ExtendedPrice
FROM dbo.Products INNER JOIN
dbo.Categories ON dbo.Products.CategoryID = dbo.Categories.CategoryID INNER JOIN
dbo.Invoices ON dbo.Products.ProductID = dbo.Invoices.ProductID
В Access 2000 аналогичный запрос имеет вид:
SELECT Invoices.Country, Invoices.City,
Invoices.Customers.CompanyName AS
CustomerName, Invoices.Salesperson,
Invoices.OrderDate, Categories.CategoryName,
Invoices.ProductName,
Invoices.Shippers.CompanyName AS
ShipperName, Invoices.ExtendedPrice
FROM Categories INNER JOIN (Invoices INNER
JOIN Products ON Invoices.ProductID =
Products.ProductID) ON Categories.CategoryID =
Products.CategoryID;
Этот запрос обращается к представлению Invoices, содержащему сведения обо всех выписанных счетах, а также к таблицам Categories и Products, содержащим сведения о Этегориях продуктов, которые заказывались, и о самих продуктах соответственно. В результате этого запроса мы получим набор данных о заказах, включающий категорию и наименование заказанного товара, дату размещения заказа, имя сотрудника, выписавшего счет, город, страну и название компании-заказчика, а также наименование компании, отвечающей за доставку.
Для удобства сохраним этот запрос в виде представления, назвав его Invoices1. Результат обращения к этому представлению приведен на рис. 8.
Рис. 8. Результат обращения к представлению Invoices1
Какие агрегатные данные мы можем получить на основе этого представления? Обычно это ответы на вопросы типа:
Какова суммарная стоимость заказов, сделанных клиентами из Франции?
Какова суммарная стоимость заказов, сделанных клиентами из Франции и доставленных компанией Speedy Express?
Какова суммарная стоимость заказов, сделанных клиентами из Франции в 1997 году и доставленных компанией Speedy Express?
Переведем эти вопросы в запросы на языке SQL2 (табл. 1).
Таблица 1
Вопрос
SQL-запрос
Какова суммарная стоимость заказов, сделанных клиентами из Франции?
SELECT SUM (ExtendedPrice) FROM invoices1 WHERE Country=’France’
Какова суммарная стоимость заказов, сделанных клиентами из Франции и доставленных компанией Speedy Express?
SELECT SUM (ExtendedPrice) FROM invoices1 WHERE Country=’France’ AND ShipperName=’Speedy Express’
Какова суммарная стоимость заказов, сделанных клиентами из Франции в 1996 году и доставленных компанией Speedy Express?
SELECT SUM (ExtendedPrice) FROM Ord_pmt WHERE CompanyName=’Speedy Express’ AND OrderDate BETWEEN ‘December 31, 1995’ AND ‘April 1, 1996’ AND ShipperName=’Speedy Express’
Результатом любого из перечисленных выше запросов является число. Если в первом из запросов заменить параметр ‘France’ на ‘Austria’ или на название иной страны, можно снова выполнить этот запрос и получить другое число. Выполнив эту процедуру со всеми странами, мы получим следующий набор данных (ниже показан фрагмент):
Country
SUM (ExtendedPrice)
Argentina
7327.3
Austria
110788.4
Belgium
28491.65
Brazil
97407.74
Canada
46190.1
Denmark
28392.32
Finland
15296.35
France
69185.48
Germany
209373.6
…
…
Полученный набор агрегатных значений (в данном случае — сумм) может быть интерпретирован как одномерный набор данных. Этот же набор данных можно получить и в результате запроса с предложением GROUP BY следующего вида:
SELECT Country, SUM (ExtendedPrice) FROM invoices1
GROUP BY Country
Теперь обратимся ко второму из приведенных выше запросов, который содержит два условия в предложении WHERE. Если выполнять этот запрос, подставляя в него все возможные значения параметров Country и ShipperName, мы получим двухмерный набор данных следующего вида (ниже показан фрагмент):
ShipperName
Country
Federal Shipping
Speedy Express
United Package
Argentina
1 210.30
1 816.20
5 092.60
Austria
40 870.77
41 004.13
46 128.93
Belgium
11 393.30
4 717.56
17 713.99
Brazil
16 514.56
35 398.14
55 013.08
Canada
19 598.78
5 440.42
25 157.08
Denmark
18 295.30
6 573.97
7 791.74
Finland
4 889.84
5 966.21
7 954.00
France
28 737.23
21 140.18
31 480.90
Germany
53 474.88
94 847.12
81 962.58
…
…
…
…
Такой набор данных называется сводной таблицей (pivot table) или кросс-таблицей (cross table, crosstab). Создавать подобные таблицы позволяют многие электронные таблицы и настольные СУБД — от Paradox для DOS до Microsoft Excel 2000. Вот так, например, выглядит подобный запрос в Microsoft Access 2000:
TRANSFORM Sum(Invoices1.ExtendedPrice) AS SumOfExtendedPrice
SELECT Invoices1.Country
FROM Invoices1
GROUP BY Invoices1.Country
PIVOT Invoices1.ShipperName;
Агрегатные данные для подобной сводной таблицы можно получить и с помощью обычного запроса GROUP BY:
SELECT Country,ShipperName, SUM (ExtendedPrice) FROM invoices1
GROUP BY COUNTRY,ShipperName
Отметим, однако, что результатом этого запроса будет не сама сводная таблица, а лишь набор агрегатных данных для ее построения (ниже показан фрагмент):
Country
ShipperName
SUM (ExtendedPrice)
Argentina
Federal Shipping
845.5
Austria
Federal Shipping
35696.78
Belgium
Federal Shipping
8747.3
Brazil
Federal Shipping
13998.26
…
…
…
Третий из рассмотренных выше запросов имеет уже три параметра в условии WHERE. Варьируя их, мы получим трехмерный набор данных (рис. 9).
Рис. 9. Трехмерный набор агрегатных данных
Ячейки куба, показанного на рис. 6, содержат агрегатные данные, соответствующие находящимся на осях куба значениям параметров запроса в предложении WHERE.
Можно получить набор двухмерных таблиц с помощью сечения куба плоскостями, параллельными его граням (для их обозначения используют термины cross-sections и slices).
Очевидно, что данные, содержащиеся в ячейках куба, можно получить и с помощью соответствующего запроса с предложением GROUP BY. Кроме того, некоторые электронные таблицы (в частности, Microsoft Excel 2000) также позволяют построить трехмерный набор данных и просматривать различные сечения куба, параллельные его грани, изображенной на листе рабочей книги (workbook).
Если в предложении WHERE содержится четыре или более параметров, результирующий набор значений (также называемый OLAP-кубом) может быть 4-мерным, 5-мерным и т.д.
Рассмотрев, что представляют собой многомерные OLAP-кубы, перейдем к некоторым ключевым терминам и понятиям, используемым при многомерном анализе данных.
Некоторые термины и понятия
Наряду с суммами в ячейках OLAP-куба могут содержаться результаты выполнения иных агрегатных функций языка SQL, таких как MIN, MAX, AVG, COUNT, а в некоторых случаях — и других (дисперсии, среднеквадратичного отклонения и т.д.). Для описания значений данных в ячейках, используется термин summary (в общем случае в одном кубе их может быть несколько), для обозначения исходных данных, на основе которых они вычисляются, — термин measure, а для обозначения параметров запросов — термин dimension (переводимый на русский язык обычно как «измерение», когда речь идет об OLAP-кубах, и как «размерность», когда речь идет о хранилищах данных). Значения, откладываемые на осях, называются членами измерений (members).
Говоря об измерениях, следует упомянуть о том, что значения, наносимые на оси, могут иметь различные уровни детализации. Например, нас может интересовать суммарная стоимость заказов, сделанных клиентами в разных странах, либо суммарная стоимость заказов, сделанных иногородними клиентами или даже отдельными клиентами. Естественно, результирующий набор агрегатных данных во втором и третьем случаях будет более детальным, чем в первом. Заметим, что возможность получения агрегатных данных с различной степенью детализации соответствует одному из требований, предъявляемых к хранилищам данных, — требованию доступности различных срезов данных для сравнения и анализа.
Поскольку в рассмотренном примере в общем случае в каждой стране может быть несколько городов, а в городе — несколько клиентов, можно говорить об иерархиях значений в измерениях. В этом случае на первом уровне иерархии располагаются страны, на втором — города, а на третьем — клиенты (рис. 10).
Рис. 10. Иерархия в измерении, связанном с географическим положением клиентов
Отметим, что иерархии могут быть сбалансированными (balanced), как, например, иерархия, представленная на рис. 10, а также иерархии, основанные на данных типа «дата—время», и несбалансированными (unbalanced). Типичный пример несбалансированной иерархии — иерархия типа «начальник—подчиненный» (ее можно построить, например, используя значения поля Salesperson исходного набора данных из рассмотренного выше примера), представлен на рис. 11.
Иногда для таких иерархий используется термин Parent-child hierarchy.
Рис. 11. Несбалансированная иерархия
Существуют также иерархии, занимающие промежуточное положение между сбалансированными и несбалансированными (они обозначаются термином ragged — «неровный»). Обычно они содержат такие члены, логические «родители» которых находятся не на непосредственно вышестоящем уровне (например, в географической иерархии есть уровни Country, City и State, но при этом в наборе данных имеются страны, не имеющие штатов или регионов между уровнями Country и City; рис. 12).
]
Рис. 12. «Неровная» иерархия
Отметим, что несбалансированные и «неровные» иерархии поддерживаются далеко не всеми OLAP-средствами. Например, в Microsoft Analysis Services 2000 поддерживаются оба типа иерархии, а в Microsoft OLAP Services 7.0 — только сбалансированные. Различным в разных OLAP-средствах может быть и число уровней иерархии, и максимально допустимое число членов одного уровня, и максимально возможное число самих измерений.
Заключение:
В данном разделе мы ознакомились с основами OLAP. Мы узнали следующее:
Назначение хранилищ данных — предоставление пользователям информации для статистического анализа и принятия управленческих решений.
Хранилища данных должны обеспечивать высокую скорость получения данных, возможность получения и сравнения так называемых срезов данных, а также непротиворечивость, полноту и достоверность данных.
OLAP (On-Line Analytical Processing) является ключевым компонентом построения и применения хранилищ данных. Эта технология основана на построении многомерных наборов данных — OLAP-кубов, оси которого содержат параметры, а ячейки — зависящие от них агрегатные данные.
Приложения с OLAP-функциональностью должны предоставлять пользователю результаты анализа за приемлемое время, осуществлять логический и статистический анализ, поддерживать многопользовательский доступ к данным, осуществлять многомерное концептуальное представление данных и иметь возможность обращаться к любой нужной информации.
Кроме того, мы рассмотрели основные принципы логической организации OLAP-кубов, а также узнали основные термины и понятия, применяемые при многомерном ЭШелизе. И, наконец, мы выяснили, что представляют собой различные типы иерархий в измерениях OLAP-кубов.
В следующей статье данного цикла мы рассмотрим типичную структуру хранилищ данных, поговорим о том, что представляет собой клиентский и серверный OLAP, а также остановимся на некоторых технических аспектах многомерного хранения данных.
Типичная структура хранилищ данных
Как мы уже знаем, конечной целью использования OLAP является анализ данных и представление результатов этого анализа в виде, удобном для восприятия и принятия решений. Основная идея OLAP заключается в построении многомерных кубов, которые будут доступны для пользовательских запросов. Однако исходные данные для построения OLAP-кубов обычно хранятся в реляционных базах данных. Нередко это специализированные реляционные базы данных, называемые также хранилищами данных (Data Warehouse). В отличие от так называемых оперативных баз данных, с которыми работают приложения, модифицирующие данные, хранилища данных предназначены исключительно для обработки и анализа информации, поэтому проектируются они таким образом, чтобы время выполнения запросов к ним было минимальным. Обычно данные копируются в хранилище из оперативных баз данных согласно определенному расписанию.
Типичная структура хранилища данных существенно отличается от структуры обычной реляционной СУБД. Как правило, эта структура денормализована (это позволяет повысить скорость выполнения запросов), поэтому может допускать избыточность данных.
Для дальнейших примеров мы снова воспользуемся базой данных Northwind, входящей в комплекты поставки Microsoft SQL Server и Microsoft Access. Ее структура данных приведена на рис. 13.
Рис. 13. Структура базы данных Northwind
Основными составляющими структуры хранилищ данных являются таблица фактов (fact table) и таблицы измерений (dimension tables).
Таблица фактов
Таблица фактов является основной таблицей хранилища данных. Как правило, она содержит сведения об объектах или событиях, совокупность которых будет в дальнейшем анализироваться. Обычно говорят о четырех наиболее часто встречающихся типах фактов. К ним относятся:
факты, связанные с транзакциями (Transaction facts). Они основаны на отдельных событиях (типичными примерами которых являются телефонный звонок или снятие денег со счета с помощью банкомата);
факты, связанные с «моментальными снимками» (Snapshot facts). Основаны на состоянии объекта (например, банковского счета) в определенные моменты времени, например на конец дня или месяца. Типичными примерами таких фактов являются объем продаж за день или дневная выручка;
факты, связанные с элементами документа (Line-item facts). Основаны на том или ином документе (например, счете за товар или услуги) и содержат подробную информацию об элементах этого документа (например, количестве, цене, проценте скидки);
факты, связанные с событиями или состоянием объекта (Event or state facts). Представляют возникновение события без подробностей о нем (например, просто факт продажи или факт отсутствия таковой без иных подробностей).
Для примера рассмотрим факты, связанные с элементами документа (в данном случае счета, выставленного за товар).
Таблица фактов, как правило, содержит уникальный составной ключ, объединяющий первичные ключи таблиц измерений. Чаще всего это целочисленные значения либо значения типа «дата/время» — ведь таблица фактов может содержать сотни тысяч или даже миллионы записей, и хранить в ней повторяющиеся текстовые описания, как правило, невыгодно — лучше поместить их в меньшие по объему таблицы измерений. При этом как ключевые, так и некоторые неключевые поля должны соответствовать будущим измерениям OLAP-куба. Помимо этого таблица фактов содержит одно или несколько числовых полей, на основании которых в дальнейшем будут получены агрегатные данные.
Пример таблицы фактов, которая может быть построена на основе базы данных Northwind, приведен на 4.
Рис. 14. Пример таблицы фактов
В данном примере измерениям будущего куба соответствуют первые шесть полей, а агрегатным данным — последние четыре.
Отметим, что для многомерного анализа пригодны таблицы фактов, содержащие как можно более подробные данные (то есть соответствующие членам нижних уровней иерархии соответствующих измерений). В данном случае предпочтительнее взять за основу факты продажи товаров отдельным заказчикам, а не суммы продаж для разных стран — последние все равно будут вычислены OLAP-средством. Исключение можно сделать, пожалуй, только для клиентских OLAP-средств (о них мы поговорим чуть позже), поскольку в силу ряда ограничений они не могут манипулировать большими объемами данных.
Отметим, что в таблице фактов нет никаких сведений о том, как группировать записи при вычислении агрегатных данных. Например, в ней есть идентификаторы продуктов или клиентов, но отсутствует информация о том, к какой категории относится данный продукт или в каком городе находится данный клиент. Эти сведения, в дальнейшем используемые для построения иерархий в измерениях куба, содержатся в таблицах измерений.
Таблицы измерений
Таблицы измерений содержат неизменяемые либо редко изменяемые данные. В подавляющем большинстве случаев эти данные представляют собой по одной записи для каждого члена нижнего уровня иерархии в измерении. Таблицы измерений также содержат как минимум одно описательное поле (обычно с именем члена измерения) и, как правило, целочисленное ключевое поле (обычно это суррогатный ключ1) для однозначной идентификации члена измерения. Если будущее измерение, основанное на данной таблице измерений, содержит иерархию, то таблица измерений также может содержать поля, указывающие на «родителя» данного члена в этой иерархии. Нередко (но не всегда) таблица измерений может содержать и поля, указывающие на «прародителей», и иных «предков» в данной иерархии (это обычно характерно для сбалансированных иерархий), а также дополнительные атрибуты членов измерений, содержавшиеся в исходной оперативной базе данных (например, адреса и телефоны клиентов).
Каждая таблица измерений должна находиться в отношении «один ко многим» с таблицей фактов.
Отметим, что скорость роста таблиц измерений должна быть незначительной по сравнению со скоростью роста таблицы фактов; например, добавление новой записи в таблицу измерений, характеризующую товары, производится только при появлении нового товара, не продававшегося ранее.
Пример таблицы измерений приведен на рис. 15.
Рис. 15. Пример таблицы измерений
Одно измерение куба может содержаться как в одной таблице (в том числе и при наличии нескольких уровней иерархии), так и в нескольких связанных таблицах, соответствующих различным уровням иерархии в измерении. Если каждое измерение содержится в одной таблице, такая схема хранилища данных носит название «звезда» (star schema). Пример такой схемы приведен на рис. 16.
Рис. 16. Пример схемы «звезда»
Если же хотя бы одно измерение содержится в нескольких связанных таблицах, такая схема хранилища данных носит название «снежинка» (snowflake schema). Дополнительные таблицы измерений в такой схеме, обычно соответствующие верхним уровням иерархии измерения и находящиеся в соотношении «один ко многим» в главной таблице измерений, соответствующей нижнему уровню иерархии, иногда называют консольными таблицами (outrigger table). Пример схемы «снежинка» приведен на 17.
Рис. 17. Пример схемы «снежинка»
Отметим, что даже при наличии иерархических измерений с целью повышения скорости выполнения запросов к хранилищу данных нередко предпочтение отдается схеме «звезда».
Однако не все хранилища данных проектируются по двум приведенным выше схемам. Так, довольно часто вместо ключевого поля для измерения, содержащего данные типа «дата», и соответствующей таблицы измерений сама таблица фактов может содержать ключевое поле типа «дата». В этом случае соответствующая таблица измерений просто отсутствует.
В случае несбалансированной иерархии (например, такой, которая может быть основана на таблице Employees базы данных Northwind, имеющей поле EmployeeID, которое одновременно является и первичным, и внешним ключом и отражает подчиненность одних сотрудников другим (см. рис. 10) в схему «снежинка» также следует вносить коррективы. В этом случае обычно в таблице измерений присутствует связь, аналогичная соответствующей связи в оперативной базе данных.
Еще один пример отступления от правил — наличие нескольких разных иерархий для одного и того же измерения. Типичные примеры таких иерархий — иерархии для календарного и финансового года (при условии, что финансовый год начинается не с 1 января), или с различными способами группировки членов измерения (например, группировать товары можно по категориям, а можно и по компаниям-поставщикам). В этом случае таблица измерений содержит поля для всех возможных иерархий с одними и теми же членами нижнего уровня, но с разными членами верхних уровней (пример такой таблицы приведен на рис. 12).
Как мы уже отмечали выше, таблица измерений может содержать поля, не имеющие отношения к иерархиям и представляющие собой просто дополнительные атрибуты членов измерений (member properties). Иногда такие атрибуты могут быть использованы при анализе данных.
Более подробно о проектировании хранилищ данных и одном из CASE-инструментов, способных упростить процесс их создания, — CA Erwin, рассказано в статье Сергея Маклакова «Хранилища данных и их проектирование с помощью CA Erwin», КомпьютерПресс, CD-ROM № 1’2001).
Следует сказать, что для создания реляционных хранилищ данных нередко ЭШеляяются специализированные СУБД, хранение данных в которых оптимизировано с точки зрения скорости выполнения запросов. Примером такого продукта является Sybase Adaptive Server IQ, реализующий нетрадиционный способ хранения данных в таблицах (не по строкам, а по столбцам). Однако создавать хранилища можно и в обычных ЭШеляонных СУБД.
Итак, обсудив типичную структуру хранилища данных, на основе которых обычно строятся OLAP-кубы, вернемся к созданию OLAP-кубов и поговорим о том, какими бывают OLAP-инструменты.
OLAP на клиенте и на сервере
Многомерный анализ данных может быть произведен с помощью различных средств, которые условно можно разделить на клиентские и серверные OLAP-средства.
Клиентские OLAP-средства представляют собой приложения, осуществляющие вычисление агрегатных данных (сумм, средних величин, максимальных или минимальных значений) и их отображение, при этом сами агрегатные данные содержатся в ЭШе внутри адресного пространства такого OLAP-средства.
Если исходные данные содержатся в настольной СУБД, вычисление агрегатных данных производится самим OLAP-средством. Если же источник исходных данных — серверная СУБД, многие из клиентских OLAP-средств посылают на сервер SQL-запросы, содержащие оператор GROUP BY, и в результате получают агрегатные данные, вычисленные на сервере.
Как правило, OLAP-функциональность реализована в средствах статистической обработки данных (из продуктов этого класса на российском рынке широко распространены продукты компаний StatSoft и SPSS) и в некоторых электронных таблицах. В частности, неплохими средствами многомерного анализа обладает Microsoft Excel 2000. С помощью этого продукта можно создать и сохранить в виде файла небольшой локальный многомерный OLAP-куб и отобразить его двух- или трехмерные сечения.
Многие средства разработки содержат библиотеки классов или компонентов, позволяющие создавать приложения, реализующие простейшую OLAP-функциональность (такие, например, как компоненты DecisionCube в Borland Delphi и Borland C++Builder). Помимо этого многие компании предлагают элементы управления ActiveX и другие библиотеки, реализующие подобную функциональность.
Отметим, что клиентские OLAP-средства применяются, как правило, при малом числе измерений (обычно рекомендуется не более шести) и небольшом разнообразии значений этих параметров, — ведь полученные агрегатные данные должны умещаться в адресном пространстве подобного средства, а их количество растет экспоненциально при увеличении числа измерений. Поэтому даже самые примитивные клиентские OLAP-средства, как правило, позволяют произвести предварительный подсчет объема требуемой оперативной памяти для создания в ней многомерного куба.
Многие (но не все!) клиентские OLAP-средства позволяют сохранить содержимое ЭШе с агрегатными данными в виде файла, что, в свою очередь, позволяет не производить их повторное вычисление. Отметим, что нередко такая возможность используется для отчуждения агрегатных данных с целью передачи их другим организациям или для публикации. Типичным примером таких отчуждаемых агрегатных данных является статистика заболеваемости в разных регионах и в различных возрастных группах, которая является открытой информацией, публикуемой министерствами здравоохранения различных стран и Всемирной организацией здравоохранения. При этом собственно исходные данные, представляющие собой сведения о конкретных случаях заболеваний, являются конфиденциальными данными медицинских учреждений, которые ни в коем случае не должны попадать в руки страховых компаний и тем более становиться достоянием гласности.
Идея сохранения ЭШе с агрегатными данными в файле получила свое дальнейшее развитие в серверных OLAP-средствах, в которых сохранение и изменение агрегатных данных, а также поддержка содержащего их хранилища осуществляются отдельным приложением или процессом, называемым OLAP-сервером. Клиентские приложения могут запрашивать подобное многомерное хранилище и в ответ получать те или иные данные. Некоторые клиентские приложения могут также создавать такие хранилища или обновлять их в соответствии с изменившимися исходными данными.
Преимущества применения серверных OLAP-средств по сравнению с клиентскими OLAP-средствами сходны с преимуществами применения серверных СУБД по сравнению с настольными: в случае применения серверных средств вычисление и хранение агрегатных данных происходят на сервере, а клиентское приложение получает лишь результаты запросов к ним, что позволяет в общем случае снизить сетевой трафик, время выполнения запросов и требования к ресурсам, потребляемым клиентским приложением. Отметим, что средства анализа и обработки данных масштаба предприятия, как правило, базируются именно на серверных OLAP-средствах, например, таких как Oracle Express Server, Microsoft SQL Server 2000 Analysis Services, Hyperion Essbase, продуктах компаний Crystal Decisions, BusinessObjects, Cognos, SAS Institute. Поскольку все ведущие производители серверных СУБД производят (либо лицензировали у других компаний) те или иные серверные OLAP-средства, выбор их достаточно широк и почти во всех случаях можно приобрести OLAP-сервер того же производителя, что и у самого сервера баз данных.
Отметим, что многие клиентские OLAP-средства (в частности, Microsoft Excel 2000, Seagate Analysis и др.) позволяют обращаться к серверным OLAP-хранилищам, выступая в этом случае в роли клиентских приложений, выполняющих подобные запросы. Помимо этого имеется немало продуктов, представляющих собой клиентские приложения к OLAP-средствам различных производителей.
OLAP-серверы могут хранить многомерные данные разными способами, которые мы и обсудим в следующем разделе.
Технические аспекты многомерного хранения данных
В многомерных хранилищах данных содержатся агрегатные данные различной степени подробности, например, объемы продаж по дням, месяцам, годам, по категориям товаров и т.п. Цель хранения агрегатных данных — сократить время выполнения запросов, поскольку в большинстве случаев для анализа и прогнозов интересны не детальные, а суммарные данные. Поэтому при создании многомерной базы данных всегда вычисляются и сохраняются некоторые агрегатные данные.
Отметим, что сохранение всех агрегатных данных не всегда оправданно. Дело в том, что при добавлении новых измерений объем данных, составляющих куб, растет экспоненциально (иногда говорят о «взрывном росте» объема данных). Если говорить более точно, степень роста объема агрегатных данных зависит от количества измерений куба и членов измерений на различных уровнях иерархий этих измерений. Для решения проблемы «взрывного роста» применяются разнообразные схемы, позволяющие при вычислении далеко не всех возможных агрегатных данных достичь приемлемой скорости выполнения запросов.
Как исходные, так и агрегатные данные могут храниться либо в реляционных, либо в многомерных структурах. Поэтому в настоящее время применяются три способа хранения данных:
MOLAP (Multidimensional OLAP) –— исходные и агрегатные данные хранятся в многомерной базе данных. Хранение данных в многомерных структурах ЭШеляяет манипулировать данными как многомерным массивом, благодаря чему скорость вычисления агрегатных значений одинакова для любого из измерений. Однако в этом случае многомерная база данных оказывается избыточной, так как многомерные данные полностью содержат исходные реляционные данные.
ROLAP (Relational OLAP) — исходные данные остаются в той же реляционной базе данных, где они изначально и находились. Агрегатные же данные помещают в специально созданные для их хранения служебные таблицы в той же базе данных.
HOLAP (Hybrid OLAP) — исходные данные остаются в той же реляционной базе данных, где они изначально находились, а агрегатные данные хранятся в многомерной базе данных.
Некоторые OLAP-средства поддерживают хранение данных только в реляционных структурах, некоторые — только в многомерных. Однако большинство современных серверных OLAP-средств поддерживают все три способа хранения данных. Выбор способа хранения зависит от объема и структуры исходных данных, требований к скорости выполнения запросов и частоты обновления OLAP-кубов.
Отметим также, что подавляющее большинство современных OLAP-средств не хранит «пустых» значений (примером «пустого» значения может быть отсутствие продаж сезонного товара вне сезона).
Заключение
В данном разделе мы рассмотрели типичную структуру реляционных хранилищ данных. Итак, теперь мы знаем, что:
типичная структура хранилища данных существенно отличается от структуры обычной реляционной СУБД — как правило, она денормализована;
основными составляющими структуры хранилищ данных являются таблица фактов (fact table) и таблицы измерений (dimension tables);
таблица фактов является основной таблицей хранилища данных. Обычно она содержит сведения об объектах или событиях, совокупность которых будет в дальнейшем анализироваться; таблица фактов, как правило, содержит уникальный составной ключ, состоящий из первичных ключей таблиц измерений. При этом как ключевые, так и некоторые неключевые ее поля должны соответствовать будущим измерениям OLAP-куба. Помимо этого таблица фактов содержит одно или несколько числовых полей, на основании которых в дальнейшем вычисляются агрегатные данные; таблицы измерений содержат неизменяемые либо редко изменяемые данные — как правило, по одной записи для каждого члена нижнего уровня иерархии в измерении;
таблицы измерений содержат как минимум одно описательное поле и, как правило, целочисленное ключевое поле для однозначной идентификации члена измерения;
каждая таблица измерений должна находиться в отношении «один ко многим» с таблицей фактов;
если каждое измерение содержится в одной таблице измерений, такая схема хранилища данных носит название «звезда». Если же хотя бы одно измерение содержится в нескольких связанных таблицах, такая схема хранилища данных носит название «снежинка».
Далее мы обсудили особенности клиентских и серверных OLAP-средств. Мы узнали, что:
клиентские OLAP-средства представляют собой приложения, осуществляющие вычисление агрегатных данных (сумм, средних величин, максимальных или минимальных значений) и их отображение, при этом сами агрегатные данные содержатся в КЭШе внутри адресного пространства такого OLAP-средства;
в серверных OLAP-средствах сохранение и изменение агрегатных данных, а также поддержка содержащего их хранилища осуществляются отдельным приложением или процессом, называемым OLAP-сервером;
в случае применения серверных средств вычисление и хранение агрегатных данных происходят на сервере, что позволяет в общем случае снизить требования к ресурсам, потребляемым клиентским приложением, а также сетевой трафик и время выполнения запросов.
наконец, мы рассмотрели различные технические аспекты многомерного хранения данных. Мы узнали, что в настоящее время применяются три способа хранения данных:
MOLAP (Multidimensional OLAP) — и детальные, и агрегатные данные хранятся в многомерной базе данных. В этом случае многомерные данные полностью содержат исходные детальные данные;
ROLAP (Relational OLAP) — детальные данные остаются в той же реляционной базе данных, где они находились изначально. Агрегатные же данные помещаются в специально созданные для их хранения служебные таблицы в той же самой базе данных;
HOLAP (Hybrid OLAP) — детальные данные остаются в той же реляционной базе данных, где они и находились изначально, а агрегатные данные хранятся в многомерной базе данных.
Мы также узнали, что подавляющее большинство современных OLAP-средств не хранит «пустых» значений.
Условные сокращения и обозначения
Усл.сокр.
Обозначения
ИС
Информационная система
ЗИВС
Защищенная информационно-вычислительная сеть
ХД
Хранилище данных
ПО
Программное обеспечение
ТЗ
Техническое задание
БД
База данных
МБД
Многомерная БД
СУБД
Система управления базой данных
АБД
Администратор БД
СППР
Система Поддержки Принятия Решений
OLAP
On-LineAnalyticalProcess (технология Оперативной Обработки Данных)
OLTP
On-Line Transactional Process
ODS
Operational Data Store (Оперативный склад данных)
SQL
Structured Query Language
PL/SQL
Процедурный язык Oracle
OWB
Oracle Warehouse Builder
OEM
Oracle Enterprise Manager
MOLAP
Технология многомерной интерактивной аналитической обработки
ROLAP
Реляционная OLAP
HOLAP
Гибрид MOLAP иROLAP
Словарь
Склад данных (СД, data warehouse, DWH): база данных, содержащая предварительно обработанные исходные ("сырые", "операционные" и т. д.) данные. Цель обработки состоит в том, чтобы сделать данные пригодными и удобными для аналитического использования разными классами пользователей, сохранив при этом информативность исходных данных. На практике склад данных обычно имеет структуру специфичного вида (типа "звезда" или "хлопьев"), в которой в целом не выполняется требование реляционной нормализации.
Секция данных (data mart): относительно небольшой склад данных или же часть более общего склада данных, специфицированная для использования конкретным подразделением в организации и/или определенной группой пользователей. Если в корпоративной системе имеется две "секции данных", то общие данные, имеющиеся в обеих секциях одновременно, должны быть представлены в секциях идентично. Термин, неустоявшийся в русском языке.
Исследование данных (data mining): метод поиска информации в данных, подразумевающий использование статистических, оптимизационных и других математических алгоритмов, позволяющих находить взаимозависимости данных (корреляция, классификация и т. д.) и синтезировать дедуктивную информацию.
Первичная обработка данных (data cleansing and scrubbing): процедура "очистки" исходных данных, заключающаяся в устранении избыточности и противоречивости и в очищении от шума перед помещением в склад данных. Более сложная обработка может включать восстановление пропущенных в исходных данных значений.
Администратор данных (data steward): новый вид специалиста, отвечающего за полноту и качество данных, помещаемых в склад данных.
Информационная система руководителя (ИСР, executive information system, EIS): компьютерная система, позволяющая получать информацию, создавать ее и предоставлять в распоряжение старшего управляющего персонала с ограниченным опытом обращения с ЭВМ. Должна предоставляться имеющаяся информация по конкретным возникающим запросам с любой допустимой степенью детализации. Также играет важную роль в стратегическом управлении организацией.
Огромная база данных (точнее всего - сверхбольшая; огромный, или сверхбольшой, склад данных, very large database, VLDB): термин для обозначения БД объемов, близких к технологически возможным максимальным границам. В настоящее время таким объемом условно может считаться объем порядка 1 Тбайт. Сверхбольшие базы и склады данных требуют особых подходов к логическому и системно-техническому проектированию, обычно выполняемому в рамках самостоятельного проекта. В сочетании с математическими средствами обработки данных они дают новое качество работы с данными, являясь в то же время весьма дорогостоящими проектами.
Система поддержки принятия решений (СППР, decision support system, DSS): система, обеспечивающая на базе имеющихся данных получение средним управляющим звеном информации, необходимой для тактического планирования и деятельности. Опирается в значительной степени на анализ данных в БД (по современным представлениям - в складе данных) визуальными средствами (графики) и средней сложности статистическими или иными математическими методами. Системы поддержки принятия решений появились давно, однако получили новый импульс к развитию с возникновением складов данных.
Сложный анализ данных (intelligent data analysis): общий термин для обозначения анализа данных с активным использованием математических методов и алгоритмов, таких как методы оптимизации, генетические алгоритмы, распознавание образов, статистические методы и т. д., а также использующих результаты их применения методов визуального представления данных. Образно смысл использования сложного анализа данных может быть сведен к формулировке "получения информации из [исходных] данных".
Список использованных источников
1. Архипенков С., Голубев Д., Максименко О. ХРАНИЛИЩА ДАННЫХ. От концепции до внедрения - М.: ДИАЛОГ-МИФИ, 2002.
2. Спирли, Эрик. Корпоративные хранилища данных. Планирование, разработка, реализация. Том 1. – М. : Издательский дом «Вильямс», 2001.
3. M.Lea Shaw Data Warehouse Database Design. Student guide - Oracle Corporaton, 2001
4. Richard A.Green Oracle iDS Implement Warehouse Builder. Student guide - Oracle Corporaton, 2001 .
5. Материалы Web-сервера http://www.oracle.ru/ .
6. Материалы Web-сервера http://www.olap.ru/ .
7. Материалы Web-сервера http://www.sybase.ru/ .
8. Материалы Web-сервера http://www.interface.ru/ .
9. Когаловский М.Р. Энциклопедия технологий баз данных. Эволюция и стандарты. Инфраструктура. Терминология. – Москва: "Финансы и статистика", 2002.
10. Шпеник М., Следж О. и др. Руководство администратора баз данных. Microsoft SQL Server 7.0. – Москва-Санкт-петербург-Киев: "Вильямс", 1999.
11. IDC: Data Warehousing Tools: Market Forecast and Analysis, 2000-2004.

Нравится материал? Поддержи автора!
Ещё документы из категории разное:
Чтобы скачать документ, порекомендуйте, пожалуйста, его своим друзьям в любой соц. сети.
После чего кнопка «СКАЧАТЬ» станет доступной!
Кнопочки находятся чуть ниже. Спасибо!
Кнопки:
Скачать документ