«Разработка алгоритма распознавания фонем русского языка с использованием вейвлет анализа и метода опорных векторов»








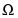
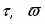 БЕЛОРУССКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ
БЕЛОРУССКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ
Выпускная работа по
«Основам информационных технологий»
Магистрант
кафедры физической электроники
факультета радиофизики и электроники
Сорока Александр
Руководители:
доцент Хейдоров Игорь Эдуардович,
ст. преподаватель Кожич Павел Павлович
Минск – 2009 г.
Оглавление
Перечень условных обозначений
МОВ – метод опорных векторов
МРЕ – минимальная речевая единица
МЧКК – мелчастотные кепстральные коэффициенты
НС – нейронная сеть
СММ – скрытая Марковская модель
eRBF – экспоненциальная радиальная базисная функция
Реферат на тему «Разработка алгоритма распознавания фонем русского языка с использованием вейвлет анализа и метода опорных векторов»
Введение
В конце XX и начале XXI века наблюдается стремительное развитие информационных технологий. Одним из приоритетных направлений исследований в данной области являются задачи хранения, обработки и передачи мультимедиа данных. К сожалению, до сих пор во многих задачах анализа мультимедиа данных компьютер так и не смог окончательно заменить эксперта. Это такие задачи, как синхронный перевод, автоматическая сегментация изображений и видеопоследовательностей, автоматическая стенография. Одной из основных задач обработки мультимедиа информации является задача распознавания и анализа естественной речи человека [8].
В задачу анализа речи входит широкий спектр задач. Традиционно их подразделяют на три подкласса: задачи идентификации, классификации и диагностики. К задачам идентификации относят задачи верификации и идентификации дикторов. К задачам классификации относят задачи распознавания ключевых слов, распознавания слитной речи и задачи семантического анализа речи. К классу задач диагностики относят задачи определения психофизического состояния диктора. Во многих из выше перечисленных задач в последние годы был достигнут значительный прогресс. Скажем, алгоритмы идентификации или верификации дикторов широко используются при проведении криминалистических процедур или для разграничения прав доступа, благодаря высокой точности разработанных методов.
По-прежнему сохраняет свою актуальность задача распознавания слитной речи [3]. Область применения полученных решений довольно обширна: автоматические стенографы, автоматизированные справочные терминалы с речевым управлением, синхронные переводчики, системы сжатия и передачи речевого сигнала с высоким качеством, системы сегментации, индексации и поиска мультимедиа информации.
Методы, которые используются при построении данных систем, активно разрабатываются последние несколько десятилетий, однако по физической сути являются базовыми методами анализа речевых сигналов, разработанными в первой половине прошлого века и в данный момент практически достигшие предела своих возможностей. Разработаны и инновационные методики анализа речевых сигналов, но к сожалению они ещё не получили широкого распространения в силу отсутствия их качественных программно-аппаратных реализаций. В настоящее время исследователи все чаще отказываются от снижения избыточности речевого сигнала, а в отдельных случаях, даже дополняют акустический сигнал сигналами иного рода, скажем параметрическим описанием движений губ говорящего или неявным вводом контекста произношения для более уверенного распознавания речевого сигнала [5].
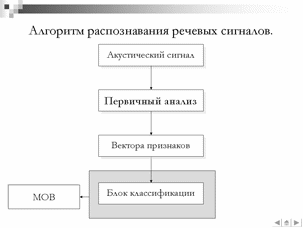
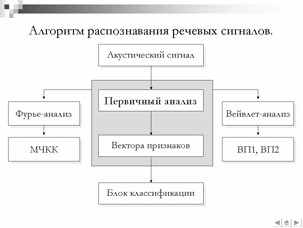
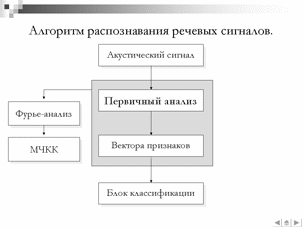
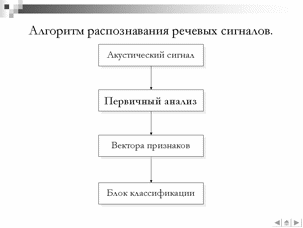
Одним из основных недостатков существующих моделей является низкая точность распознавания акустически схожих минимальных единиц речи, в качестве которых выступают фонемы, аллофоны или более сложные структурные единицы речи. В связи с данным фактом в данной работе проводятся исследования по возможности улучшения характеристик системы распознавания за счет изменения блока классификации распознающей системы. Так, вместо традиционного распознавания акустико-фонетических единиц с использованием скрытых Марковских моделей (СММ) был использован метод опорных векторов (МОВ) . В качестве методов первичного анализа использовались ставшие традиционными методы спектрального и кепстрального представлений и малораспространенный метод вейвлет-анализа.
Глава Акустико-фонетическиое моделирование речевого сигнала
Фонетическое моделирование речевого сигнала.
Основой моделирования речевого сигнала на фонетическом уровне является построение иерархической структуры состоящей из элементов, которые получили название минимальных речевых единиц (МРЕ) .
В большинстве случаев, в качестве таких единиц используются аллофоны, дифоны, трифоны, слоги и фонемы. Аллофон – набор звуков, имеющих одинаковое признаковое описание. Дифоны – переход между двумя аллофонами без их стационарных участков, чаще всего переход согласный-гласный или гласный-согласный. Трифон – последовательность из трех аллофонов, позволяющая учитывать коартикуляционное воздействие предыдущего и последующего звуков на текущий звук. Фонема – совокупность аллофонов, имеющих одинаковые функции в речеобразовании и не несущие семантических различий. Слог – ядро гласного звука и функционально и формально связанные с ним соседние согласные звуки [6, 7].
В качестве МРЕ могут быть так же использованы и слова. Но для распознавания русского языка использование слов в качестве МРЕ ведет к большим расходом вычислительных ресурсов, в силу того, что слово в русском языке обладает порядка 100 словоформ, все из которых являются возможными МРЕ. Кроме того, для устойчивого распознавания в словаре для каждой МРЕ могут хранится признаковые описания всего класса МРЕ, что ведет к дополнительному расходу ресурсов. Так же, значительно усложняется процесс обучения готовой системы распознавания, построенной с таким использованием такого подхода, так как каждому диктору необходимо произнести каждую МРЕ несколько раз для получения устойчивых эталонов.
С учетом вышеизложенного, можно определить основные требования к МРЕ:
1. Словарь МРЕ должен обладать минимальным возможным размером.
2. Алгоритм сегментации речевого сигнала на МРЕ должен по возможности затрачивать минимальные временно-аппаратные ресурсы.
3. Алгоритм классификации каждой МРЕ также должен минимизировать затраты.
4. МРЕ должны иметь устойчивую классификацию на всем словаре.
Данным требованием удовлетворяют МРЕ, представляющие собой участки речевого сигнала фиксированной длительности, соответствующие фазам фонем или самим фонемам. Количество фонем в русском языке равно 42, из них 6 гласных и 36 согласных. Акустические свойства фонем определяются артикуляторными особенностями их образования – местом и способом.
Место образования гласных фонем обусловлено положением тела языка и губ. Место образования согласных фонем определяется положением щели в ротовой полости, а также заднее или переднее положение языка. Способ образования фонем характеризует динамические и энергетические характеристики речевого образа [7].
Сложность использования фонем в качестве МРЕ заключается в том, что в речевом сигнале, соответствующем разговорной речи, фонемы в «чистом» виде не встречаются по причине того, что фонемы способны изменять свои акустико-артикуляторные параметры в зависимости от окружения. Таким образом, в разговорной речи возникают модификации фонем – аллофоны, число которых резко увеличивается, в сравнении с числом фонем, а именно 480 для гласных и 8800 для согласных. Аллофоны можно разделить на позиционные и комбинаторные. Комбинаторные аллофоны возникают в результате влияния фонетического окружения на текущую фонему и наложение процессов артикуляции – эффект коартикуляции. Позиционные аллофоны возникают в результате изменения звучания фонемы в зависимости от положения к ударному слогу или другим фонемам – эффект редукции. Кроме того, фонемы расположенные рядом на плоскости «место-способ» имеют схожие признаковые описания, как следствие, распознающая система имеет низкую точность классификации схожих фонем, в результате чего, возникают ошибки «замены» для фонем одной группы. Традиционно, разделение близкорасположенных фонем не выделяют в отдельный этап идентификации фонем, а разделимость образов повышают использованием более информационных признаковых описаний.
Преимущество использования фонем в качестве МРЕ очевидно – малый размер словаря и простота фонетической модели. Для построения малого словаря в исследовательских целях нет необходимости в использовании большой базы данных для обучения, что так же является значительным преимуществом, в силу высоких материальных затрат, необходимых для создания большой обучающей базы.
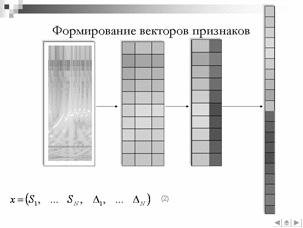
Построение векторов признаков речевых сигналов на основе вейвлет-преобразования.
Признаком. называется отображение 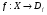 , где
, где 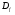 - пространство возможных значений признака. Вектор
- пространство возможных значений признака. Вектор 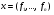 ,
, 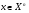 называется вектором признаков., отождествляемым с самим объектом, и является математическим описанием образа в системах классификации. Пространство
называется вектором признаков., отождествляемым с самим объектом, и является математическим описанием образа в системах классификации. Пространство 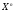 называется пространством признаков. В зависимости от пространства возможных значений признаков существует несколько обобщенных типов признаков таких, как бинарные, номинальные, порядковые и количественные. Наиболее часто используются количественные признаки, пространством возможных значений которых является пространство рациональных чисел.
называется пространством признаков. В зависимости от пространства возможных значений признаков существует несколько обобщенных типов признаков таких, как бинарные, номинальные, порядковые и количественные. Наиболее часто используются количественные признаки, пространством возможных значений которых является пространство рациональных чисел.
В качестве критерия выбора используемых признаков принят принцип наибольшей информативности признака, для получения более устойчивых алгоритмов классификации.
Традиционно, вектора признаков речевых сигналов получают в результате спектрального анализа исследуемого сигнала с использованием преобразования Фурье На данный момент ведутся исследования по извлечению векторов признаков с использованием вейвлет преобразований, однако значительных результатов в данной области на сегодня не достигнуто. Для построения векторов признаков широко используются знания о психоакустическом восприятии человеком звуковых сигналов.
В рамках данной работы разработан следующий алгоритм извлечения векторов признаков для речевых сигналов на основе вейвлет-анализа Определим набор двумерных фильтров в пространстве «частота-время»:
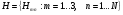 , (1)
, (1)
где
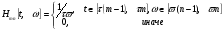 , (2)
, (2)
в свою очередь - ширина фильтра во временной и частотной области соответственно, N – параметр, определяемый экспериментально.
Ширина фильтра во временной области может быть найдена из следующего выражения:
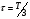 , (3)
, (3)
где Т – длительность фонемы.
Ширина фильтра в частотной области может быть найдена из выражения
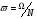 , (4)
, (4)
где - ширина частотной области вейвлет образа.
Тогда вектор признаков может быть сформирован как
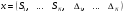 , (5)
, (5)
где
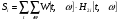 , (6)
, (6)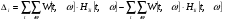 (7)
(7)
Параметры 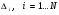 введены для учета динамических процессов в начале и конце фонемы, обусловленных эффектами редукции и коартикуляции.
введены для учета динамических процессов в начале и конце фонемы, обусловленных эффектами редукции и коартикуляции.
Глава Методологические основы распознавания речевых сигналов.
Основные подходы к решению задачи распознавания речевых сигналов.
Существует большое множество методов решения задачи распознавания речевых сигналов, все они могут быть разделены на два наиболее общих подхода – дискриминантный и структурный. Исторически первым был дискриминатный подход, который в литературе так же называют эталонным или теорико-информационным [10]. Суть данного подхода – формирование пространства признаков речевых образов, в котором схожие речевые образы формируют генеральные совокупности – таксоны или кластеры. Для описания собственных областей таких кластеров используются функции плотности вероятности, которые в своих реализациях приобретают экстремальные значения. Параметры, а также внешний вид функций плотностей вероятностей определяются в ходе обучения на обучающей выборке. Принадлежность поступившего речевого образа к какому-либо конкретному кластеру в ходе процесса распознавания определятся при помощи решающего правила, которое в большинстве случаев записывается в виде дискриминантной функции.
Данный подход обладает рядом недостатков. Во-первых, в силу ограниченности мощности обучающей выборки приводит к использованию оценок вместо истинно статистических характеристик функций плотности вероятностей для каждого кластера, что влечет за собой нарушение условий оптимальности классификаторов, построенных на статистических решающих критериях, а, следовательно, и к ошибкам распознавания. Во-вторых, данный метод не может напрямую применяться к речевым сигналам в задачах распознавания слитной речи в силу высокой вариативности естественной речи и, как следствие, невозможности составления актуальной обучающей выборки со всеми возможными прецедентами.
Данных недостатков лишен структурный подход. Структурный подход – это метод распознавания речевых образов на основе теории формальных грамматик, когда конечный речевой сигнал представляется в виде иерархического набора структурных единиц.
Точность определения отдельной минимальной акустико-фонетической единицы речи, как правило, не высока и не превышает 80% [9], а значит большой вклад в точность окончательного распознавания вносят принятые фонетические, синтаксические и лексические модели языка. Основным преимуществом структурного подхода является тот факт, что акустико-фонетических единиц на несколько порядков меньше, чем всех возможных словоформ, что значительно уменьшает временные затраты полученных алгоритмов, в сравнении дискриминантным подходом.
Идентификация минимальных речевых единиц.
Задача классификации МРЕ представляет собой классическую задачу распознавания образов, которая может быть сформулирована следующим образом. Пусть имеются 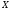 - множество признаковых описаний МРЕ,
- множество признаковых описаний МРЕ, 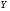 - множество наименований классов МРЕ,
- множество наименований классов МРЕ,  - целевая зависимость, значения которой известны для объектов обучающей выборки
- целевая зависимость, значения которой известны для объектов обучающей выборки 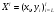 . Требуется построить алгоритм
. Требуется построить алгоритм 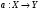 , который будет аппроксимировать целевую зависимость на всем пространстве .
, который будет аппроксимировать целевую зависимость на всем пространстве .
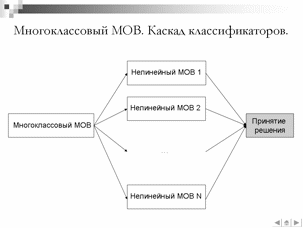
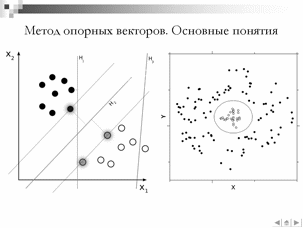
В данной работе в качестве алгоритма классификации был выбран МОВ [2], что отличается от широко распространенного подхода с использованием скрытых Марковских моделей. Данный подход аргументирован тем фактом, что СММ фактически не является классификатором и не обладает разделяющей способностью. В ходе обучения СММ минимизируются внутриклассовые расстояния, но не максимизируются межклассовые расстояния, в силу чего алгоритм классификации не позволяют распознавать фонемы расположенные рядом на плоскости классификации «место-способ». Предполагается, что МОВ обеспечит более высокую точность классификации близко расположенных фонем в силу максимизации межклассовых отступов в процессе обучения.
Глава Экспериментальное исследование характеристик разработанных алгоритмов
В рамках данной работы проведена серия экспериментов по поиску оптимальных характеристик разработанных методов и алгоритмов анализа и распознавания речевых сигналов. Для проведения данных экспериментов был реализован перечень программ на языке высокоуровнего программирования С++.
Экспериментальное исследование характеристик алгоритма извлечения векторов признаков.
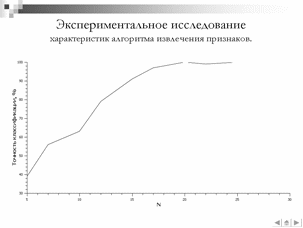
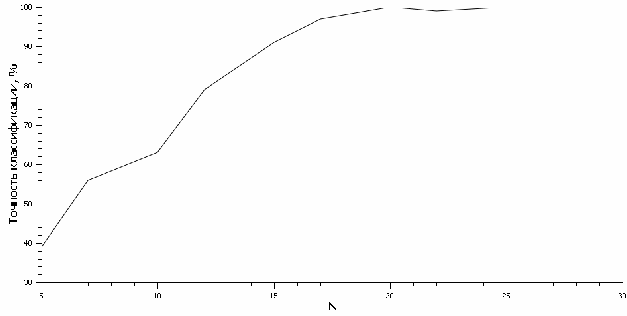
Для разработанного алгоритма извлечения векторов признаков эксперимент по определению оптимального числа фильтров в частотной области N. В ходе данного эксперимента исследована зависимость точности классификации изолированной фонемы в зависимости от N . Для проведения эксперимента была сформирована база данных из 300 звуковых реализаций фонемы [а] и 700 звуковых реализаций согласных фонем. Выбор фонем в обучающей выборке обусловлен тем фактом, что акустические сигналы фонемы [а] и согласных фонем значительно отличаются, следовательно, в качестве критерия нахождения оптимального параметра можно установить достижение абсолютной разделимости обучающей выборки, то есть достижение стопроцентной точности при тестировании. Для тестирования была сформирована выборка из 50 звуковых реализаций фонемы [а] и 50 реализаций различных согласных фонем. Обучающая и контрольная выборки представляют собой непересекающиеся множества. В качестве классификатора выбран МОВ с ядром eRBF. В качестве базисной функции вейвлет-преобразования использовался вейвлет Хаара. Результаты эксперимента представлены на рисунке Рисунок
Рисунок Зависимость точности классификации от параметра N
Анализ результатов эксперимента показывает, что оптимальным значением является N = 20 при точности классификации в 97%.
Так же был проведен эксперимент по сравнению характеристик разработанного алгоритма с традиционным подходом с использованием МЧКК. Для данного эксперимента была сформирована обучающая выборка из 1000 звуков различных фонем русского языка, из которых 500 соответствуют фонеме [а] и тестовая выборка из 200 звуковых реализаций фонемы [а] русского языка. Тестовая и обучающая выборки представляют собой непересекающеюся множества. В качестве классификатора использовался нелинейный МОВ с подбором оптимальных параметров методом кросспроверки. Точность классификации с использованием разработанного алгоритма составила 81.3%, что на 2% превышает точность классификации с использованием МЧКК Таким образом, точность классификации с использованием МЧКК и разработанного алгоритма на основе вейвлет-преобразования отличается незначительно, однако, методика извлечения признаков из речевых сигналов с использованием вейвлет–преобразования обладает более высоким потенциалом для оптимизации.
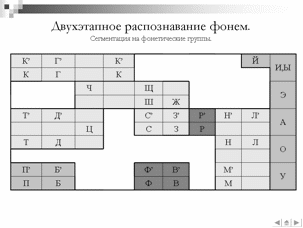
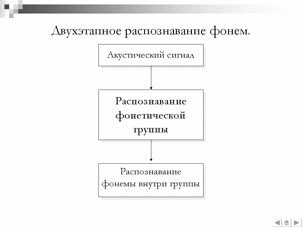
Исследование разработанного алгоритма распознавания речевых сигналов.
Так же проведена серия экспериментов по распознавания акустически схожих речевых сигналов для алгоритма описанного в разделе . Данная серия экспериментов включает эксперимент по классификации фонем по группам и эксперимент по точной идентификации фонемы внутри группы. Разделение процедуры идентификации фонемы на два этапа вызвано тем, что точность классификации отдельной фонемы среди всех фонем русского языка не превышает 82%, как показали предыдущие эксперименты. В связи с этим, сделана попытка разделить фонемы на группы близкорасположенных в признаковом пространстве фонем, а в последствии разделить фонемы в группе дополнительным классификатором. Для проведения данного эксперимента была сформирована обучающая выборка из 4500 звуковых реализаций фонем, в среднем 100 реализаций на каждую фонему. В качестве тестовой выборки использовались 100 реализаций на каждую из четырех фонем: [а, м, н, д]. Фонемы сегментированы на 9 групп по расположению на плоскости классификации «место-способ». Обучение классификаторов первого этапа осуществлялось по схеме «каждый против всех», второго этапа – «каждый против каждого». Оптимальные параметры нелинейных классификаторов определялись методом кросспроверки с использованием 25% обучающей выборки в качестве контрольных данных.
Для сравнения характеристик разработанных алгоритмов проведено сравнительное тестирование с использованием алгоритма на основе нейронных сетей (НС). Результаты экспериментов приведены в таблицах Таблица , Таблица , Таблица .
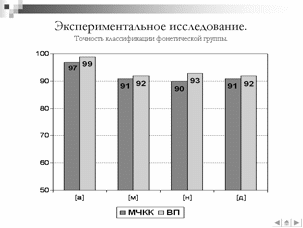
Таблица – Результаты эксперимента по точности идентификации фонемы с использованием МЧКК
[а]
[м]
[н]
[д]
Точность определения группы, %
97
91
90
91
Точность определения фонемы внутри группы, %
89
84
83
89
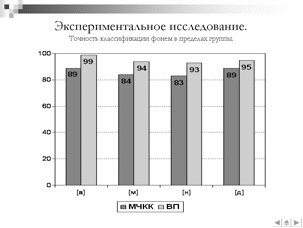
Таблица – Результаты эксперимента по точности идентификации фонемы с использованием разработанного алгоритма извлечения векторов признаков.
[а]
[м]
[н]
[д]
Точность определения группы, %
99
92
93
92
Точность определения фонемы внутри группы, %
99
94
93
95
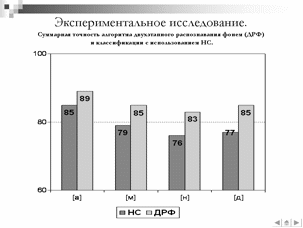
Таблица – Суммарная точность предложенного алгоритма и классификации с использованием НС.
[а]
[м]
[н]
[д]
Суммарная точность предложенного алгоритма, %
89
85
83
85
Точность классификатора на основе НС, %
85
79
76
77
Анализ результатов данных экспериментов показал, что точность классификации фонем с использованием разработанного алгоритма превышает точность традиционного алгоритма на основе нейронных сетей в среднем на 6%.
Глава Заключение
В ходе данной работы были получены следующие результаты.
Сформирована база акустических сигналов размером в 5000 звуковых реализаций различных фонем.
Разработан и исследован новый метод формирования векторов признаков на основе вейвлет преобразования Использование данного метода показало результаты, превосходящие результаты использования широко используемых методов формирования векторов признаков МЧКК на 2% при классификации фонем в общем случае и на 10% при классификации близкорасположенных в признаковом пространстве фонем.
Разработан алгоритм двухэтапной классификации фонем на основе каскадов нелинейных МОВ с использованием разработанного алгоритма извлечения векторов признаков на основе вейвлет-преобразования, использование которого продемонстрировало результаты, превосходящие результаты алгоритма с использованием НС в среднем на 6%.
Результаты данной работы были представлены на международной научно-технической конференции, посвященной 45-летию МРТИ-БГУИР, на IX международной межвузовской научно-технической конференции студентов, магистрантов и аспирантов «Исследования и разработки в области машиностроения, энергетики и управления», VI Всероссийской научной конференции студентов, аспирантов и молодых ученых «Технологии Microsoft в теории и практике программирования» и приняты к публикации в научных журналах «Речевые технологии» №3,4 2009 (Москва), «Электроника инфо» №5 2009.
Библиографический список
Список использованных источников
. Воробьев В.И., Грибунин В.Г. Теория и практика вейвлет-преобразования // Военный университет связи, - Санкт-Петербург, 1999.
. Местецкий Л.М. Математические методы распознавания образов // Курс лекций, МГУ ВМиК, кафедра «Математические методы прогнозирования», - Москва, 2002-2004.
. Пилипенко В.В. Технология распознавания большого количества образов на примере распознавания речи из сверхбольшого словаря // SpeechCon, - Москва, 2006. - C 53-54
. Солдатов С. Lip Reading: Preparing Feature Vectos // International Conference Graphicon, - Москва, 2003.
. Раев А.Н. Области применения систем идентификации дикторов, использующих разные первичные описания речи (MFCC и положение формант) // Biometrics AIA 2006 LEGS.
. Фанг Г. Акустическая теория речеобразования: Пер. с англ. // Москва, Наука, 1964, - С 284.
. Фланаган Джеймс Л. Анализ, синтез и восприятие речи // Связь, - Москва, 1968.
. Barket J.M., Deng Li, Historical development and future directions in speech recognition and understanding // Report of Speech Understanding Working Group, MINDS 2006-2007.
. Chen J.K., Lee L.S., Soong F.K. Large vocabulary, word-based mandaring dictation system // Speech communication and technology: European conf. ESCA – Madrid, 1995, p. 285 – 288.
. Luettin Juergen, Visual speech and speaker recognition // Department of Computer Science University of Sheffield, 1997.
Список публикаций
. А. Сорока А.М., Янь Цзинбинь, У Ши, Егоров В.Н., Трус А.А. Использование синтезатора речи по тексту в задачах образования // Тезисы международной научно-технической конференции, посвященной 45-летию МРТИ-БГУИР, - Минск, 2009 - С. 291.
. А. Сорока А.М., Алиев Р.М., Трус А.А., Многокомпонентная система на платформе .NET для настройки и оптимизации алгоритмов анализа аудиосигналов // Труды VI Всероссийской научной конференции студентов, аспирантов и молодых ученых «Технологии Microsoft в теории и практике программирования» - Москва, 1-2 апреля 2009г., - С 53-54.
. А. Сорока А.М., Янь Цзинбинь, У Ши, Трус А.А. Классификация аудиосигналов с использованием одноклассового метода опорных векторов для систем поиска информации в мультимедиа архивах // «Речевые технологии» №4 (факт. вр. публ. - август 2009г.), - Москва, 2008 - С 15-24.
. А. Сорока А.М., Янь Цзинбинь, Трус А.А., Хейдоров И.Э., Верификация ключевых слов на основе мер доверительности и метода опорных векторов // «Электроника инфо» №5 – Минск, 2009 - С 44-49.
.-А.Сорока А.М., Трус А.А. Алгоритм построения векторов признаков на основе вейвлет-преобразования для классификации фонем русского языка // Труды 52-й научной конференции МФТИ «Современные проблемы фундаментальных и прикладных наук», - Москва-Долгопрудный, 2009 - С 103–106.
.-А.Сорока А.М., Янь Цзинбинь Разработка метода создания сети спутывания // Труды 52-й научной конференции МФТИ «Современные проблемы фундаментальных и прикладных наук», - Москва-Долгопрудный, 2009, - С 118-120.
Предметный указатель
А
Аллофон, 5, 6, 7
комбинаторный, 7
позиционный, 7
В
Вектор признаков, 8, 9
Д
Дискриминантный подход, 10
Дифон, 6
М
мелчастотные кепстральные коэффициенты, 14, 17
метод опорных векторов, 5, 12, 13, 14, 16
Минимальная речевая еденица, 6
Минимальная речевая единица, 7, 8, 12
П
Преобразование
вейвлет, 5, 9, 13, 14, 17
Фурье, 9
Признак, 8, 9
С
скрытая Марковская Модель, 5, 12
Структурный подход, 10
Т
Таксон, 10, 11
Трифон, 6
Ф
Фонема, 5, 7, 8, 13
Э
Эффект
коартикуляции, 8
редукции, 8
Интернет ресурсы в предметной области исследования
http://www.machinelearning.ru/ - профессиональный информационно-аналитический ресурс, посвященный машинному обучению, интеллектуальному анализу данных и распознаванию образов. Содержит большое количество научных статей, постоянно обновляется. В рамках данного ресурса функционирует проект «Полигон», целью которого является создание распределенной системы тестирования алгоритмов классификации.
http://www.gotai.net – информационно-аналитический ресурс, посвященный искусственному интеллекту. Содержит уникальные статьи о нейронных сетях. Обновляется редко.
http://archive.ics.uci.edu/ml/ - репозиторий различных задач распознавания. Содержит большое число обучающих и тестовых данных в едином формате. Все объекты представлены в виде совокупности признаков, как в численном виде, так и в более сложных видах. Постоянно обновляется. Имеет сложную навигацию.
http://alglib.sources.ru/ - библиотека алгоритмов по численным методам, содержит большое число алгоритмов, позволяющих решать дифференциальные уравнения, реализующих аппарат матричных вычислений и т.д. Все алгоритмы тщательно протестированы, отложены и реализованы на языках программирования C++, C#, Pascal, VBA с использованием библиотеки матричных вычислений LAPACK. Недостатком является факт использования перегруженных классов Vector и Matrix, что не позволяет эффективно использовать данную библиотеку при разработке или модернизации существующих программ.
Личный сайт
http://dr-neiromantik.narod.ru – электронный ресурс, посвященный магистранту Белорусского Государственного Университета кафедры радиофизики Сорока Александру Михайловичу. На данном сайте представлена выпускная работа по курсу «Информационные технологии» и контактная информация.
Граф научных интересов
Смежные специальности
Основная специальность
Сопутствующие специальности
01.04.03 – радиофизика
Нелинейные динамические системы.
Статистическая радиофизика.
Акустика, включая акусто электронику.
05.27.01 – твердотель-ная электроника
Теоретические и экспериме-н тальные основы организа-ции квантовых вычислений в твердотельных структурах.
Программное обеспечение систем автоматизированного проектирования дискретных и интегральных компонентов электронной техники, прибо ров на квантовых эффектах.
01.04.04 – физическая электроника
Наноэлектроника: теорети-че ские и экспериментальные исследования квантово-раз мерных эффектов.
Физико-математическое мо делирование закономерно стей переноса зарядов в на норазмерных структурах.
Разработка физических принципов функционирова ния приборов наноэлектро ники.
01.01.09 – дискретная математика и матема тическая кибернетика
Теория и методы минимиза ции функций; общая теория экстремальных задач; теория многокритериальной и век торной оптимизации; теория и методы решения задач ма тематического программиро вания, включая задачи сто хастического программиро вания и задачи в условиях неопределенности.
01.01.07 – вычисли тельная математика
Численные методы и алго ритмы решения прикладных задач, возникающих при ма тематическом моделирова нии естественнонаучных, на учно-технических, социаль ных и других проблем.
Презентация
Вопросы к выпускной работе
<answer id="313763" right="0">нету правильного ответаanswer>
answers>
question>
Список литературы к выпускной работе
Гетц К., Джилберт М. Программирование в Microsoft Office Пер. с англ. // Санкт-Петербург, БХВ-Петербург, - 2000.
Корняков В., Программирование документов и приложений MS Office в Delphi // Санкт-Петербург, БХВ-Петербург, - 2005.
Баричев С., Афанасьев Д., Office XP // Москва, Кудиц-образ, - 2002.
Минько П. Microsoft Office PowerPoint 2007 // Москва, ЭКСМО, - 2007.
Корнеев И.К., Ксандопуло Г., Маршуцев В., Информационные технологии // Москва, Проспект, - 2009.
Джамса. К., Кинг К., Андерсон Э., Креативный web-дизайн // Москва, DiaSoft, -2005.
Веб-узел Office online [Электронный ресурс] / Microsoft, - Редмонд, США, - Режим доступа http://office.microsoft.com
Htmlbook.ru / -Режим доступа http://htmlbook.ru
Приложение 1. Список реализованных программ
В рамках данной работы были реализованы следующие программы. Для написания всех программ использовался язык высокоуровневого программирования C++, среда разработки Code::Blocks 8.02, компилятор gnu gcc 3.4.5 реализация MinGW. Для разработки графического интерфейса использовался фреймворк Qt 4.5.0.
Класс CTwoClassSVM, представляющий собой реализацию бинарного МОВ.
Класс CTwoClassSVM имеет следующий интерфейс:
class CTwoClassSVM
{
public :
CTwoClassSVM();
virtual ~CTwoClassSVM();
void initialize(const Matrix &, int dimension, double penalty);
void linearScaleData(double min = 0, double max = 1);
void learn();
double classify(Vector&);
void setKernel(kernel_type = LINEAR, double degree = 1, double coef0 = 0,
double gamma = 0);
};
Реализация данного класса по технологии COM удовлетворяет следующему интерфейсу:
ISVM : public IDispatch
{
public:
virtual /* [helpstring][id] */ HRESULT STDMETHODCALLTYPE loadSettings( /* [string][in] */ Char __RPC_FAR *__MIDL_0015,/* [out][in] */ struct ErrorStruct __RPC_FAR *__MIDL_0016) = 0;
virtual /* [helpstring][id] */ HRESULT STDMETHODCALLTYPE work(/* [out][in] */ struct DataStruct __RPC_FAR *__RPC_FAR *__MIDL_0017) = 0;
virtual /* [helpstring][id] */ HRESULT STDMETHODCALLTYPE getProcessorId(/* [string][out] */ Char __RPC_FAR *__RPC_FAR *__MIDL_0018) = 0;
virtual /* [helpstring][id] */ HRESULT STDMETHODCALLTYPE getSize(/* [out] */ int __RPC_FAR *__MIDL_0019) = 0;
virtual /* [helpstring][id] */ HRESULT STDMETHODCALLTYPE getStep(/* [out] */ int __RPC_FAR *__MIDL_0020) = 0;
virtual /* [helpstring][id] */ HRESULT STDMETHODCALLTYPE clear( void) = 0;
virtual /* [helpstring][id] */ HRESULT STDMETHODCALLTYPE getSettings(/* [string][out] */ Char __RPC_FAR *__RPC_FAR *__MIDL_0021) = 0;
};
Программа GraphSVM, позволяющая строить графическое отображение многомерных данных на двумерную плоскость методом главных компонент, проводить классификацию данных с использованием МОВ, отображать результаты классификации.
Класс GMM, являющийся реализацией алгоритма EM GMM с графической оболочкой, позволяющей отображать результаты сегментации на двумерной плоскости. Графический интерфейс проиллюстрирован на рисунке П2.
Класс имеет следующий интерфейс:
class GMM : public SegmentationMachine
{
public :
struct Param // параметры модели
{
unsigned int max_iteration; // максимальное количество итераций
unsigned int cluster_count; // количество кластеров (количество компонент в смеси)
unsigned int stab_count; // количество неизменных итераций, после которых произойдет выход
};
GMM();
virtual ~GMM();
void setParam(void* param); // установка параметров модели
void* getParam();
void clear(); // сброс обученной модели
Vector segmentation(const Matrix &data); // процедура сегментации данных data
};
Программа RoboRealmAPI для анализа вейвлет образов с использованием методов анализа и распознавания изображений, предоставляемых программой RoboRealm.
Программа SVMgridS, позволяющая подбирать оптимальные параметры классификатора на основе МОВ с использованием алгоритма поиска по сетке и метода кросспроверки.

Нравится материал? Поддержи автора!
Ещё документы из категории разное:
Чтобы скачать документ, порекомендуйте, пожалуйста, его своим друзьям в любой соц. сети.
После чего кнопка «СКАЧАТЬ» станет доступной!
Кнопочки находятся чуть ниже. Спасибо!
Кнопки:
Скачать документ